Fine-Tuning
Taking a pre-trained AI model and teaching it something specific with targeted examples.
Taking a pre-trained AI model and teaching it something specific with targeted examples.
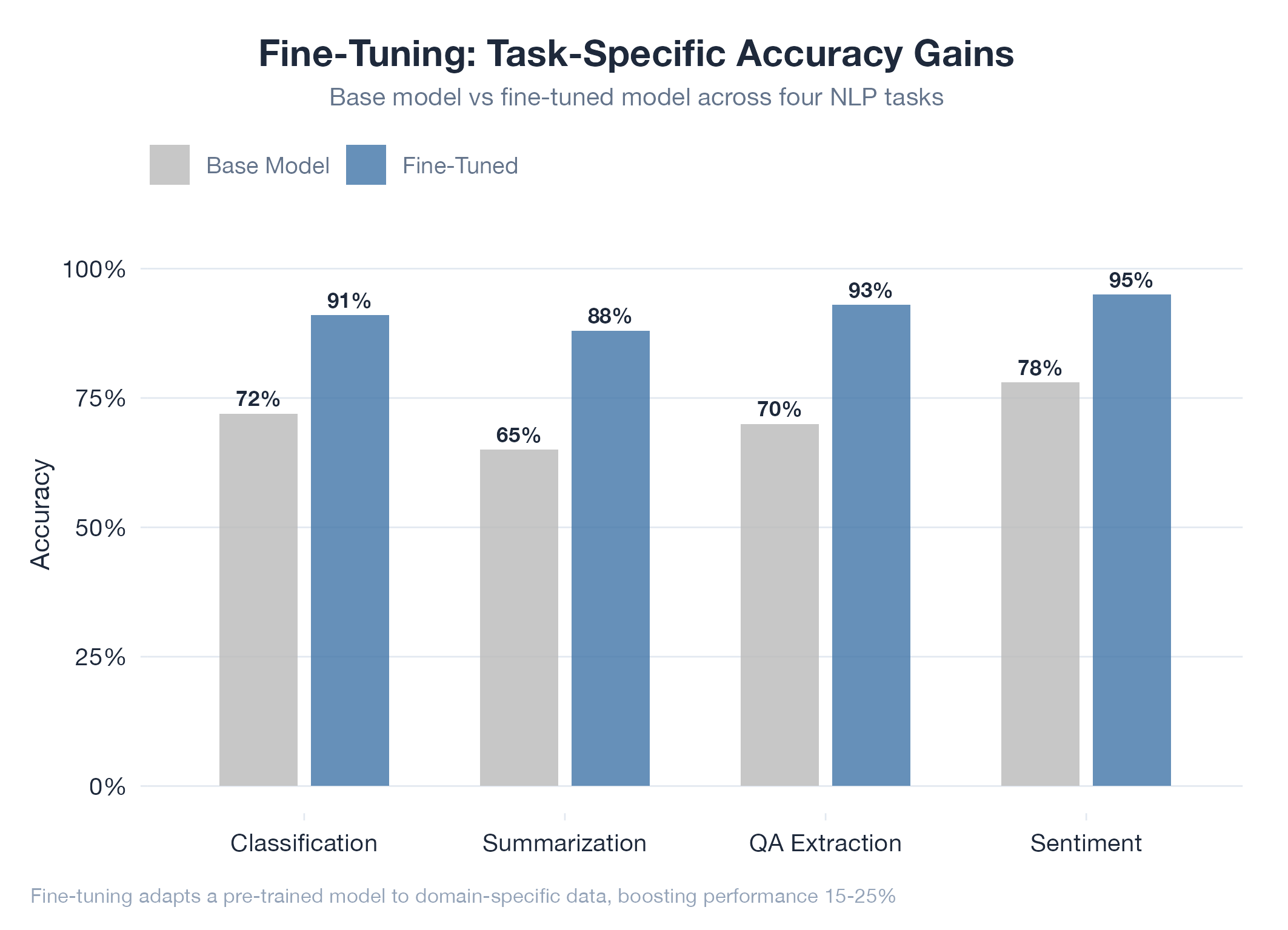
Fine-tuning takes a large pre-trained model that already understands language and reasoning, then continues training it on a smaller, targeted dataset to make it an expert at your specific task. It keeps everything it already learned but gets much better at the thing you care about. This sits between prompt engineering (no weight changes) and training from scratch (billions of tokens, millions of dollars): more powerful than prompting, far cheaper than pre-training. The main risk is catastrophic forgetting: the model improves at your task but degrades at everything else if done carelessly.
How It Works
Start with a base model → prepare curated domain examples → continue training with a low learning rate on your dataset → evaluate on held-out examples. Training typically takes hours and thousands of examples, not months and billions.
Example
The jobs-apply project uses prompt engineering and multi-model orchestration rather than fine-tuning, but the lab’s thesis work examines why a fine-tuned specialist like a coding-focused model can outperform a larger generalist on narrow tasks: the same mechanism that made ChatGPT useful by fine-tuning on conversations. Related: Embeddings and Transformer.