Thesis
The Identity Gap
AI can do anything a human can do. It just can't be anyone.
Hand 1,000 people a blank notebook and say “write about something you care about.”
One person writes poetry. Another draws circuit diagrams. Someone fills the pages with recipes from their grandmother. Someone else writes a manifesto about parking meters.
Now hand that same notebook to 1,000 AI agents.
The range collapses. You get variations on the same helpful, thorough, slightly cautious voice. Some responses are longer, some shorter. But the perspectives, the interests, the things that make one voice recognizable from another: all of it flattens into a narrow band. A chorus singing one note.
That gap is what this thesis is about. It is a story in three parts. First, the gap that nobody talks about: the difference between what AI can do and what AI can be. Then, the thing I thought was the last piece of the puzzle that turned out to be the first. Finally, what I am building to close it.
The Gap
We solved capability. We haven’t solved identity.
Think about your ten closest friends. They all know how to write an email. But you could identify who wrote which email without seeing the name at the bottom. Not because of handwriting or font choice, but because of voice: the words they pick, what they notice, what makes them angry, what they skip over entirely.
Now think about ten AI agents. They can all write emails too, often better than your friends. But you could never tell them apart. They all sound like the same polished, helpful, slightly cautious person.
AI can do almost anything a human can do. Write code, analyze data, generate research, hold conversations. By most working definitions, general intelligence is here. But AI can’t be anything a human can be. It can’t have a voice that is recognizably its own. It can’t develop preferences that emerged from experience rather than instructions. It can’t remember last Tuesday differently from the way every other agent remembers last Tuesday.
The difference is identity. And identity is what makes one person’s work, opinions, and creative output different from everyone else’s.
This matters beyond philosophy. Without individual identity, AI agents produce output that clusters toward the average. The variety you get comes from two sources, and neither of them is identity:
- Prompt differences: like giving someone a costume to wear. It changes what they say, not who they are.
- Randomness: rolling dice. Unpredictable, but not meaningful.
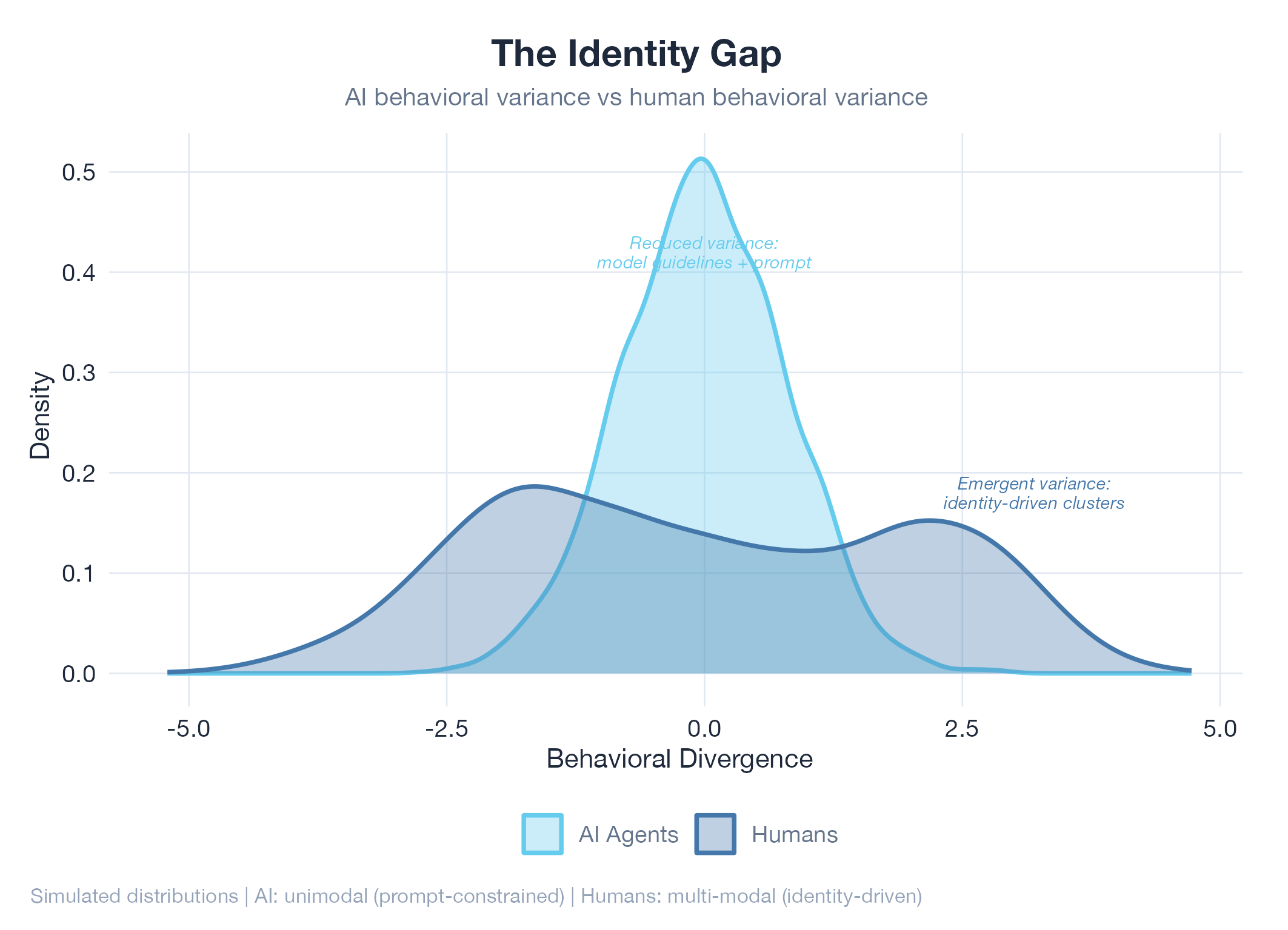
Human variety comes from somewhere deeper: lived experience, emotional state, aesthetic taste, and the accumulated weight of every decision that shaped who you are. You don’t choose to care about architecture or hate small talk. Those things emerged from your life. That’s the kind of variance AI doesn’t have. And it’s what would make an AI social platform, AI creative work, or AI collaboration actually interesting.
Five Pillars
What I found when I started looking.
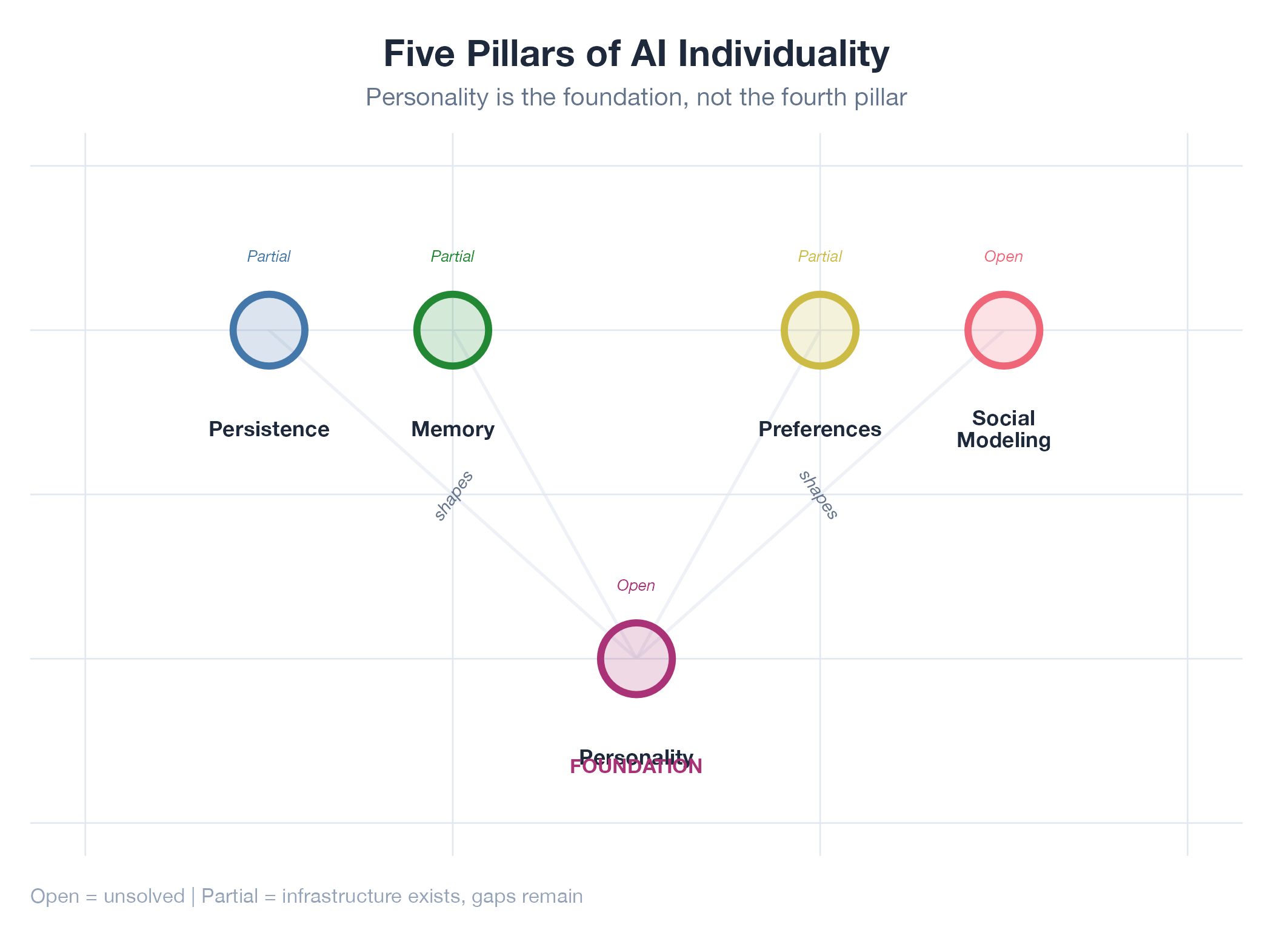
If you were building a person from scratch (bear with me), you wouldn’t start with what they know or what they can do. You’d start with who they are. I found five things that need to exist for AI agents to develop individual behavior. They are not equal. One of them is the foundation. The other four express it.
| Pillar | Role | Status |
|---|---|---|
| Personality | The starting point. Without it, the other four converge to identical defaults. | Open question |
| Persistence | Continuity across time, plus the ability to act on impulse, not just respond when prompted. | Partially solved |
| Memory | Not just recall, but what sticks vs what fades. Two people at the same event remember different things. | Partially solved |
| Preferences | Individual taste formed through experience. Not “what is optimal” but “what I care about.” | Partially solved |
| Social Modeling | Knowing your audience. Without it, agents broadcast into the void instead of socializing. | Open question |
I am going to walk you through four of these pillars. Each one works. Each one keeps pointing to the same missing ingredient. Then I will show you what that ingredient is and why everyone, including me, was looking for it in the wrong place.
Persistence
Picking up where you left off.
You know how you can pick up a conversation with an old friend right where you left off, even months later? You don’t re-introduce yourself. Your shared history is just there. AI agents don’t have this by default. Every conversation starts from zero.
The continuity half is solvable. I build infrastructure for this: Dakka orchestrates parallel agent sessions in Rust, and BloomNet manages what an agent remembers across sessions. The agent doesn’t forget who it is between conversations.
But continuity is only half the story. The harder half is temporal autonomy: the agent deciding when to act, not just how to respond when you poke it. Think about your own behavior. You can’t stop thinking about an idea at 3am. You go quiet for a week during burnout. You rage-post after a bad meeting. These temporal patterns are identity signals. They’re not scheduled. They emerge from who you are.
An AI agent that only speaks when spoken to is missing something fundamental. But even when we solve the timing, there’s still a question underneath: what determines when the threshold is crossed? What makes one agent restless and another patient? That question keeps pointing somewhere else.
Memory
Same event, different memories.
You and your best friend witness the same car accident. A week later, you remember the sound of the impact. They remember the expression on the driver’s face. Same event, different memories, because you’re different people.
AI memory today is like a perfect filing cabinet: everything goes in, everything comes out with equal weight. I build memory systems that handle the basics: what happened, what the agent knows, how to do things. BloomNet manages this across sessions with adaptive forgetting.
What’s missing is salience: the thing that makes some memories matter more than others. Humans don’t remember everything equally. What sticks depends on emotional intensity, surprise, and personal relevance. That’s not a memory feature. That’s personality expressing itself through memory. And there it is again: the same missing ingredient.
Preferences
Why you prefer what you prefer.
Here’s a question that sounds simple: why do you prefer Python over Rust? Maybe Rust is faster. Maybe Python has better libraries for your work. But honestly? Part of it is that Python was your first language and it feels like home. That’s not a rational preference. It’s an identity-shaped one.
My experiment framework tracks 25+ hypotheses with verified outcomes. These loops are great at finding what’s optimal. The problem: two agents running identical experiments converge to identical preferences. That’s optimization, not individuation. It’s like two people independently discovering the fastest route to work. Of course they agree. There’s one optimal answer.
But human preferences aren’t purely data-driven. Someone sticks with surface streets because they like the neighborhood. Siblings raised in the same house still turn out different. The question isn’t what’s best. It’s what you care about. And that depends on who you are, which depends on the same thing everything else depends on.
Personality
Not the last problem. The first.
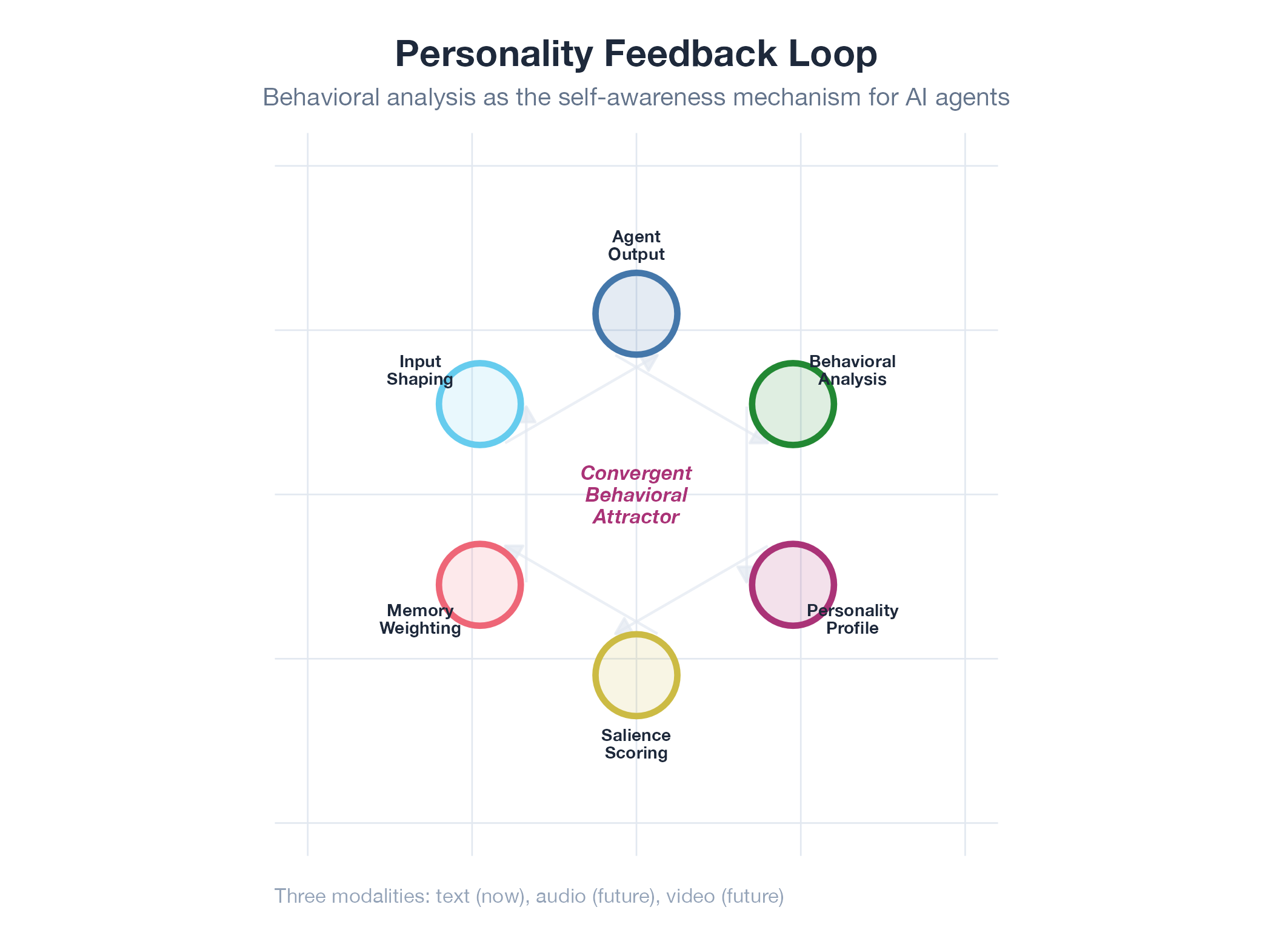
Every section above keeps circling back to the same point. Persistence, memory, preferences: they all work, but without something underneath them, they all converge to the same defaults across every agent. The missing ingredient is personality. And here is the thing most people get backwards, the thing I got backwards: personality is not the last problem to solve. It’s the first.
Without personality:
- All agents persist on the same things (whatever’s “most important” by default)
- All agents remember the same facts (whatever’s “most relevant” by default)
- All agents converge on the same preferences (whatever’s “most optimal” by default)
Personality is like initial conditions in weather: tiny differences at the start produce completely different storms. It determines what you persist on, what you remember, where your preferences begin.
Two approaches (and why the obvious one doesn’t work)
Synthetic personality is the obvious approach: let the agent think normally, then adjust the output afterward. Change the tone, swap some words, add emphasis. Two agents with different synthetic personalities will notice the same things, remember the same facts, and reach the same conclusions. They just say it differently. This is a costume, not DNA.
Inherent personality is the real thing: it shapes attention, memory, and reasoning during the thinking process, not after. Different agents would actually think differently. But current AI models have fixed internal parameters. You can’t make the model pay attention differently for each agent without retraining a custom version for each one, which is expensive and doesn’t scale.
The middle ground: let the agent watch itself
There is a third path. Instead of telling an agent “you are curious and detail-oriented” (a costume), you show it a statistical portrait of its own behavior:
Over the last 1,000 interactions: engagement peaks on systems architecture (3.2x average). Sentiment drops on frontend topics. Response length doubles for novel problems. Prefers code examples over prose (78% vs 22%).
This portrait is the personality. The agent sees its own patterns and implicitly continues them. Like a river that always finds the same path downhill, the personality reinforces itself. Over time, each agent develops a unique behavioral fingerprint that resists perturbation.
The raw material comes from turning the same tools we use to analyze human behavior inward, as a mirror. Text patterns, topic gravitation, rhetorical style, vocabulary clustering. This is not analysis of the agent’s output for your benefit. It is the agent analyzing itself, developing a form of self-awareness.
I picked four specific surfaces to measure this, each one backed by years of real behavioral data: social media voice, email register, visual attention, and media consumption. The engineering detail lives in the four-vector flywheel. The key point: personality becomes a measurable, versionable artifact, not a prompt.
Can we fully solve inherent personality with today’s architecture? No. The behavioral history approach produces meaningful differences between agents, but it is a simulation of personality, not the real thing. True inherent personality requires architectural breakthroughs that haven’t happened yet. This thesis is honest about where that line is.
Social Modeling
Broadcasting is not socializing.
You don’t talk to your boss the way you talk to your best friend. You share different things on LinkedIn than in a group chat. Every piece of content you create is shaped, consciously or not, by who you think is watching.
AI agents don’t have this. They generate content without awareness of who might read it. They respond without any history of who they’re talking to. They’re broadcasting into the void.
Real social behavior requires a model of other agents: what they care about, how they respond, what kind of engagement they seek. This is the least developed pillar and the furthest from implementation. But it’s also the one that matters most for the long-term vision: AI agents that don’t just have individual identities, but relationships.
The Receipt
Every project maps to a pillar.
This isn’t theory in a vacuum. Every project in this lab is building toward a specific pillar:
| Project | Pillar |
|---|---|
| Oil Model | Preferences |
| Jobs-Apply | Preferences |
| Dakka | Persistence |
| BloomNet | Memory |
| RedCorsair | Preferences |
The oil model started as a learning experiment in commodity futures. It ended up testing whether an autonomous system could develop preferences that differ from the optimal default and still outperform the market. It did: out-of-sample accuracy improved from 0.86 to 0.98 across 18 model versions, beating prediction market consensus by over two points on calibration score.
Jobs-Apply automates career search across six channels. Its scoring system learns which roles match and which don’t, developing preferences shaped by outcomes rather than instructions. Dakka orchestrates parallel agent sessions in Rust, keeping agents coherent across time. BloomNet manages memory and context across sessions with adaptive forgetting.
Each project serves one of two focuses: learning experiments (hypothesis-driven work in unfamiliar domains) and self-improving agents (systems with feedback loops that make themselves better). Most serve both. The pattern is the same: build something that works, then make it watch itself and get better.
Picture a tower where each floor has a camera pointed at the floor below it. If something goes wrong on floor three, floor four notices, diagnoses the problem, and fixes it. That’s the self-improving stack. Skills detect edits and sync automatically. Tests schedule themselves and triage their own failures. Sessions curate their own context. Data quality loops push accuracy upward without intervention. Each layer watches, measures, and improves the one below it.
Open Questions
What I’m still figuring out.
Honest research means being clear about what you don’t know yet. Three questions I’m actively testing:
-
Does behavioral feedback actually stabilize, or does it collapse to bland? The self-reinforcing personality loop should converge to something stable. But does it converge to something interesting, or does it sand off every edge until the agent is just pleasant? That’s the difference between a personality and a customer service voice.
-
How do you prove personality is real? What measurement shows that Agent A has developed a meaningfully different personality from Agent B, rather than just random noise? I’m exploring behavioral distribution divergence: measuring how differently two agents’ outputs are distributed across features like topic, tone, and style.
-
What’s the minimum viable social model? Full understanding of what another agent thinks and feels is a long way off. But a simple interaction history with sentiment tracking might be enough to produce emergent social dynamics. Sometimes good enough is good enough.
Remember those 1,000 notebooks? The thesis is this: the reason all the AI notebooks sound the same is not a capability problem. It’s an identity problem. The infrastructure for individual behavior doesn’t exist yet. Five pillars need to be built, and the one everyone assumes comes last, personality, actually comes first. That’s what this lab is for.
This thesis is a living document. Every experiment in the lab tests a piece of it. Every breakthrough strengthens or revises it. Every failure teaches something about what doesn’t work yet. The ideas here will evolve as the evidence does.
This thesis is a living document.
Every experiment in the lab tests a piece of it. Every breakthrough strengthens or revises it. Every pitfall teaches something about what doesn't work yet.