Embeddings
Text converted to numbers that capture meaning. Similar ideas land near each other in vector space.
Text converted to numbers that capture meaning. Similar ideas land near each other in vector space.
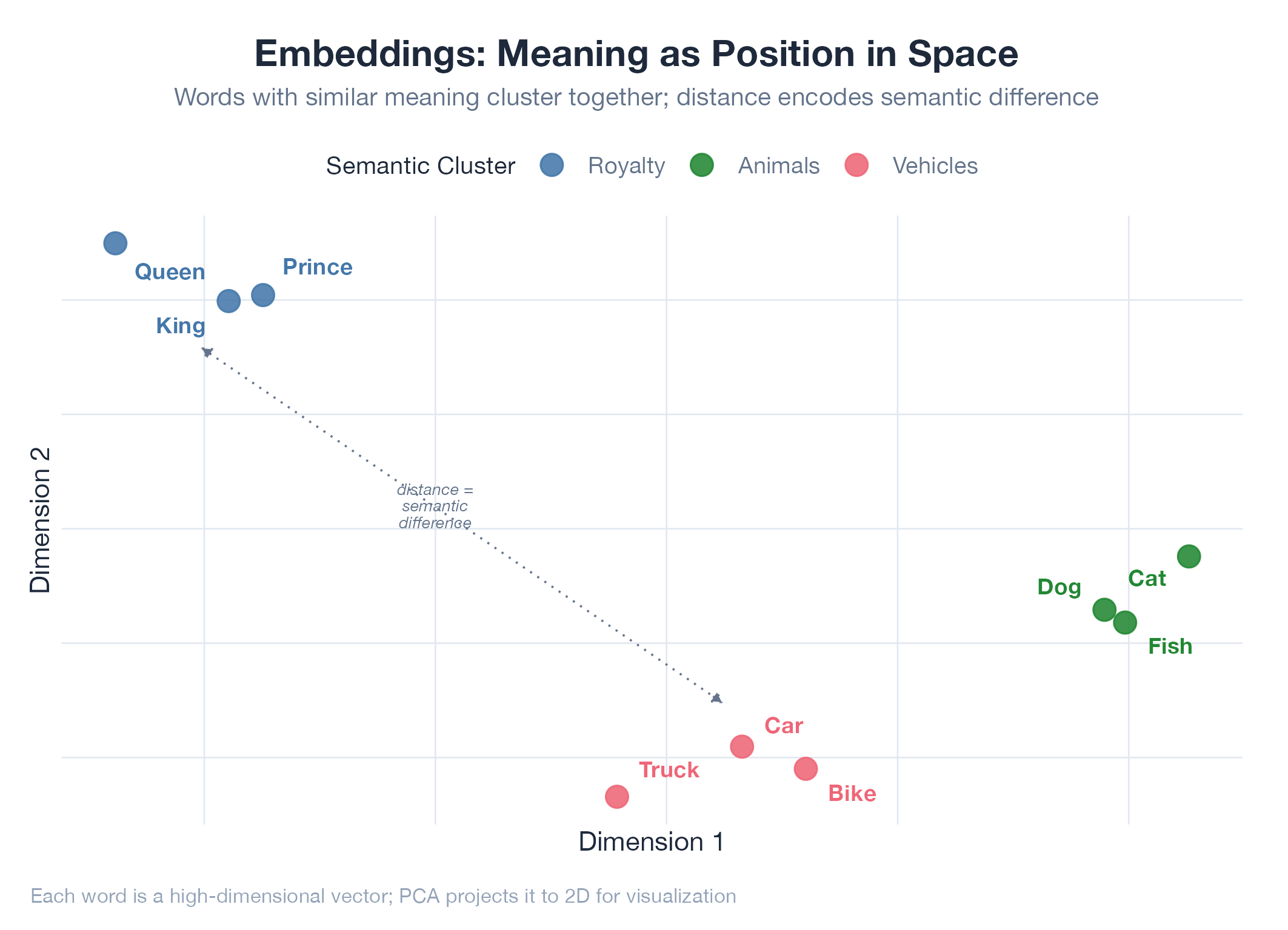
Embeddings are coordinates on a map of meaning. An embedding model converts text into a list of ~768–3,072 numbers (a vector), learned from billions of examples, that encode semantic relationships. “Dog” and “cat” land near each other. “Dog” and “algebra” are on different continents. Crucially, “The CEO resigned” and “The company’s leader stepped down” produce very similar vectors even though they share almost no words: the model has learned they mean the same thing. Similarity is measured with cosine distance: 0.95 = nearly identical, 0.30 = barely related.
How It Works
Embed both texts → compare vectors with cosine similarity → interpret score. Powers search, classification, clustering, and recommendation without any keyword matching.
Example
J-Score v2 uses embeddings as its first scoring layer. A resume saying “built data pipelines in Python” semantically matches a job posting asking for “ETL development experience”: a keyword system would miss this. The embedding layer catches 30–40% of matches that exact-match scoring drops. Detailed in J-Score v2.