Hallucination
When AI confidently says something that isn't true. Plausible fiction presented as fact.
When AI confidently says something that isn't true. Plausible fiction presented as fact.
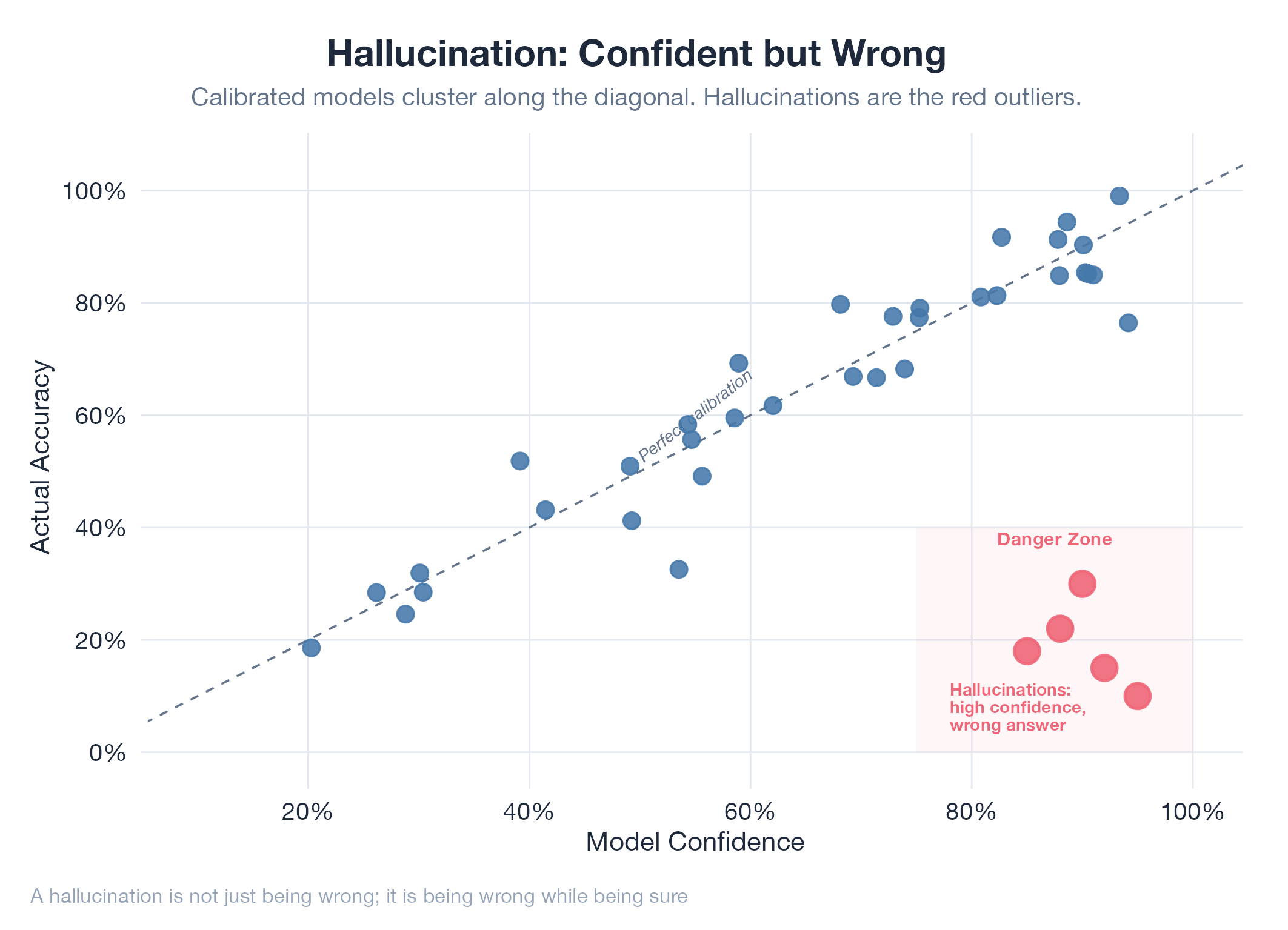
A hallucination is AI output that is confident, coherent, and wrong. Language models predict the most likely next token given the context: “likely” means statistically consistent with training data, not factually correct. The model has no internal “I’m not sure” signal; it generates uncertain content with the same fluent confidence as certain content. Common types: inventing citations, mixing up entity attributes, placing events in the wrong time period, and constructing plausible but invalid reasoning. Mitigations: RAG (give the model real documents), grounding (require source citations), and human verification on any critical output.
How It Works
Transformers attend to patterns in training data, not a fact database. Novel combinations of patterns can produce fluent output that never existed in training data. There’s no separate “truth checker”: the model’s only signal is “does this completion fit the context?”
Example
The jobs-apply CHRO audit found a cover letter hallucination bug: the AI was inventing specific achievements not in the resume. The fix was to structure prompts so every claim required a direct quote from the source document. Five pipeline bugs fixed in the audit pass at Jobs Apply CHRO Audit.