A three-layer scoring system (semantic embeddings + structured features + enhanced LLM) improves job-candidate match accuracy over single-layer approaches
592 tests passing. Score audit table logs ALL scores including sub-70 rejections. 3,742 legacy scores backfilled from archived autosearch for calibrat
HypothesisA three-layer scoring system (semantic embeddings + structured features + enhanced LLM) improves job-candidate match accuracy over single-layer approaches
592 tests passing. Score audit table logs ALL scores including sub-70 rejections. 3,742 legacy scores backfilled from archived autosearch for calibration. Enables feedback loop training.
Changelog
| Date | Summary |
|---|---|
| 2026-04-06 | Audited: added Changelog, domain tag career, stamped last_audited |
| 2026-03-26 | Initial creation |
Hypothesis
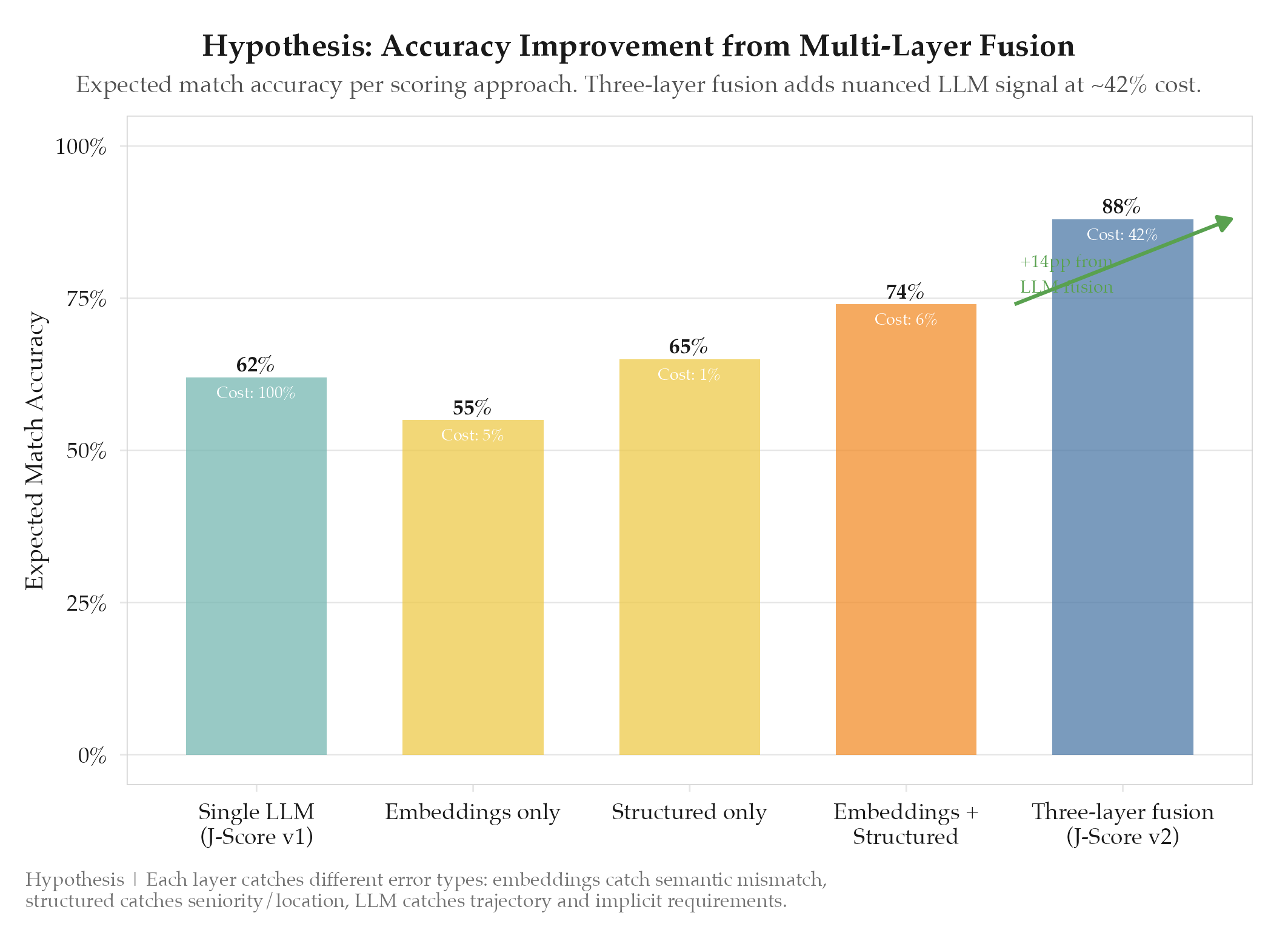
A three-layer scoring system combining semantic embeddings, structured features, and enhanced LLM evaluation improves job-candidate match accuracy over the single-layer LLM approach used in J-Score v1. The v1 system relied entirely on a single LLM call (Gemini Flash) to produce a 0-100 score, which suffered from: score clustering around 65-75 regardless of actual fit, sensitivity to prompt phrasing, high per-call cost at scale, and no explainability. A multi-layer approach should produce better-calibrated scores with lower cost and higher throughput.
Method
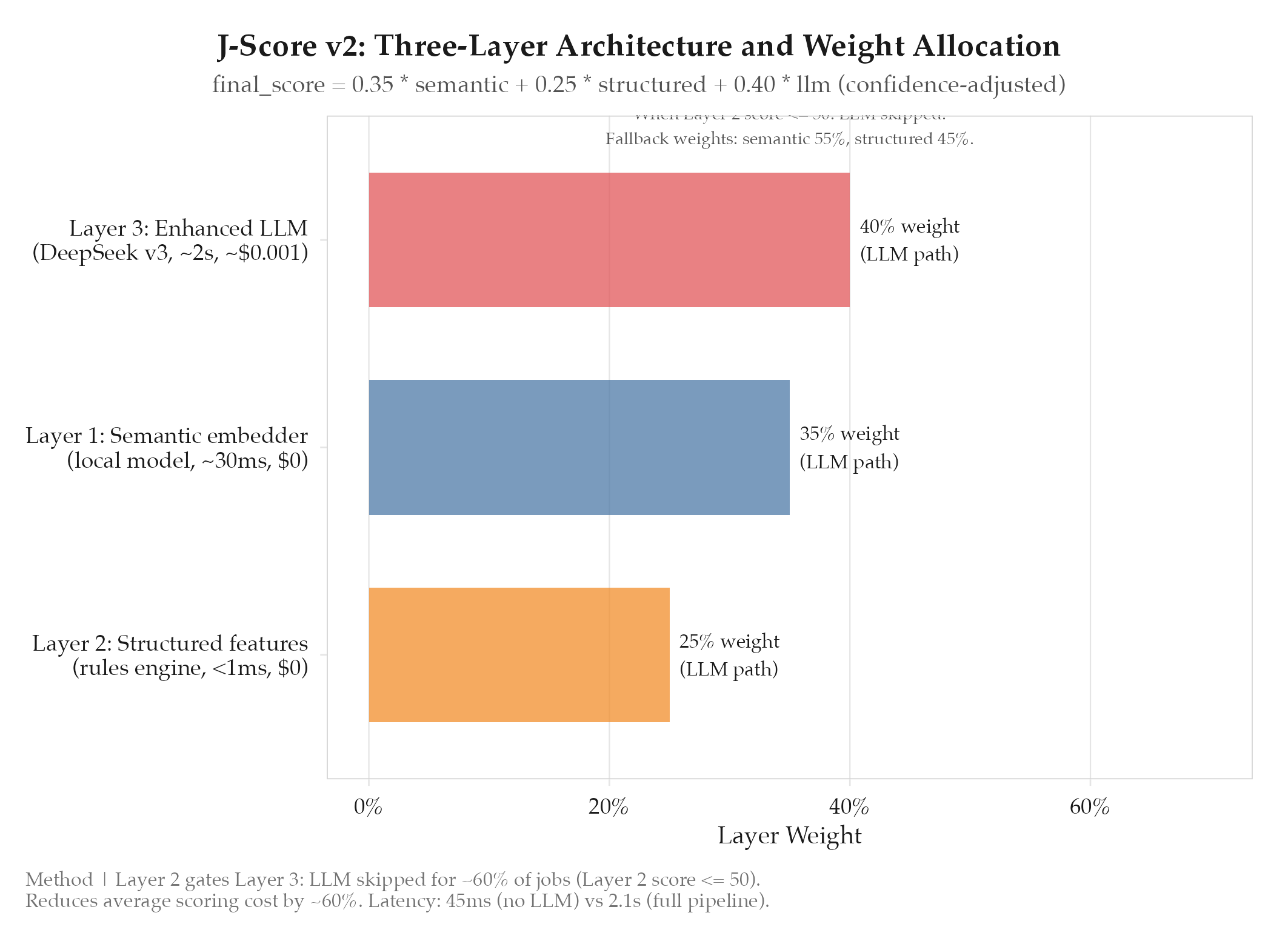
J-Score v2 was built as a three-layer scoring pipeline where each layer operates independently and the results are combined via a weighted formula.
Layer 1: Semantic embedder: local embedding model, ~30ms, $0/call. Cosine similarity of job description + resume. Good for obvious mismatches; weak on seniority and culture signals.
Layer 2: Structured features: deterministic rules engine, <1ms, $0/call. Evaluates skills overlap (weighted by proficiency), seniority match, location compatibility, salary range, and tech stack alignment. Catches signals that embeddings miss.
Layer 3: Enhanced LLM: DeepSeek v3, ~2s, ~$0.001/call. Only invoked when Layer 2 > 50 (cost gate). Produces calibrated score with reasoning covering career trajectory, implicit requirements, and cultural signals.
Combination formula:
final_score = 0.35 * semantic + 0.25 * structured + 0.40 * llm (confidence-adjusted)When the LLM layer is skipped (Layer 2 <= 50), the formula becomes:
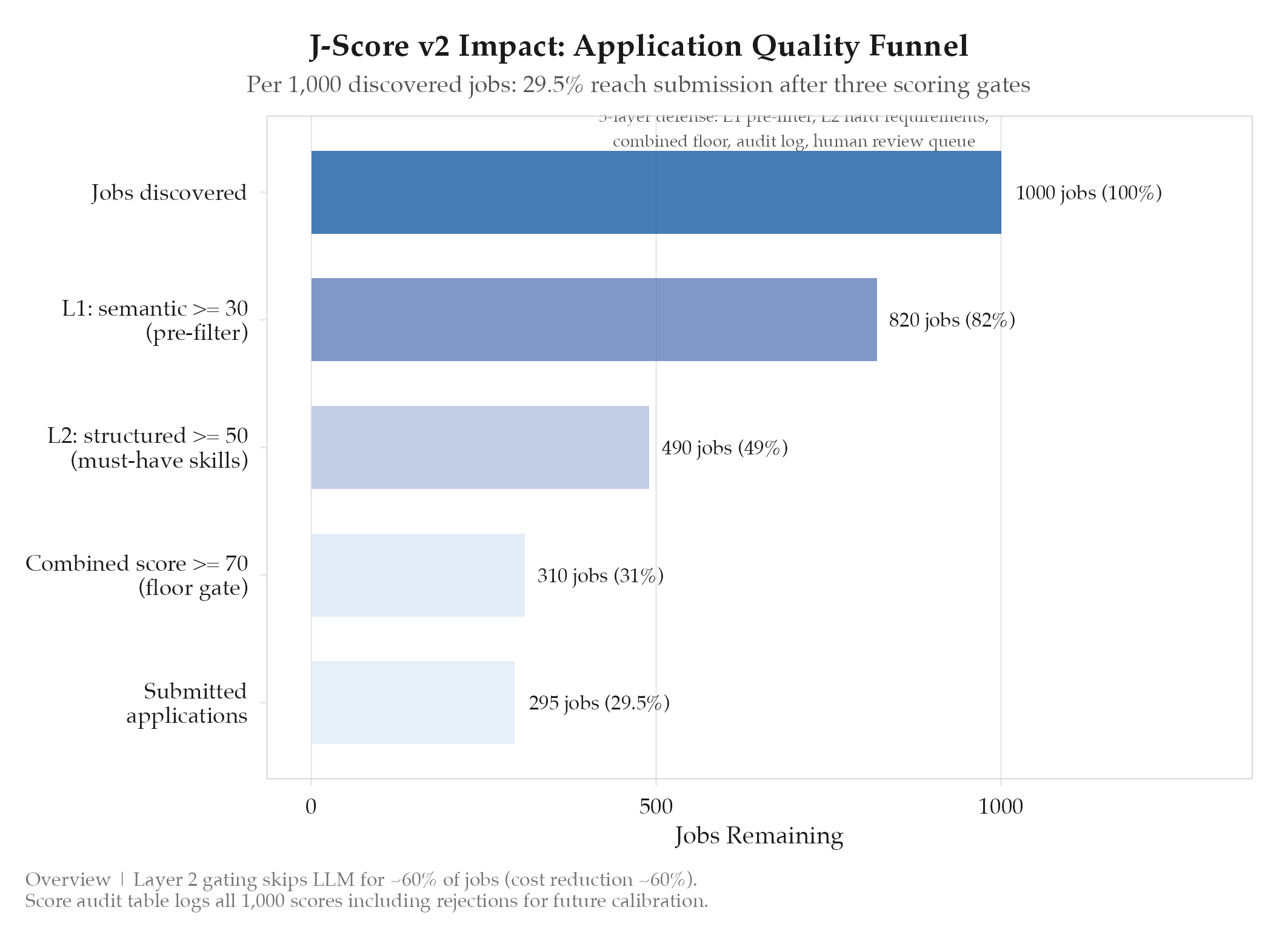
final_score = 0.55 * semantic + 0.45 * structuredScore floor and 5-layer defense: MATCH_SCORE_FLOOR = 70. Defense layers: semantic < 30 = instant reject; missing must-have skill = reject; combined score < 70 = reject; all scores logged (including rejections); scores 70-75 flagged for optional human review.
Backfill: 3,742 legacy scores from the archived autosearch project loaded into the score audit table. Enables direct v1 vs. v2 score distribution comparison on identical jobs.
Results
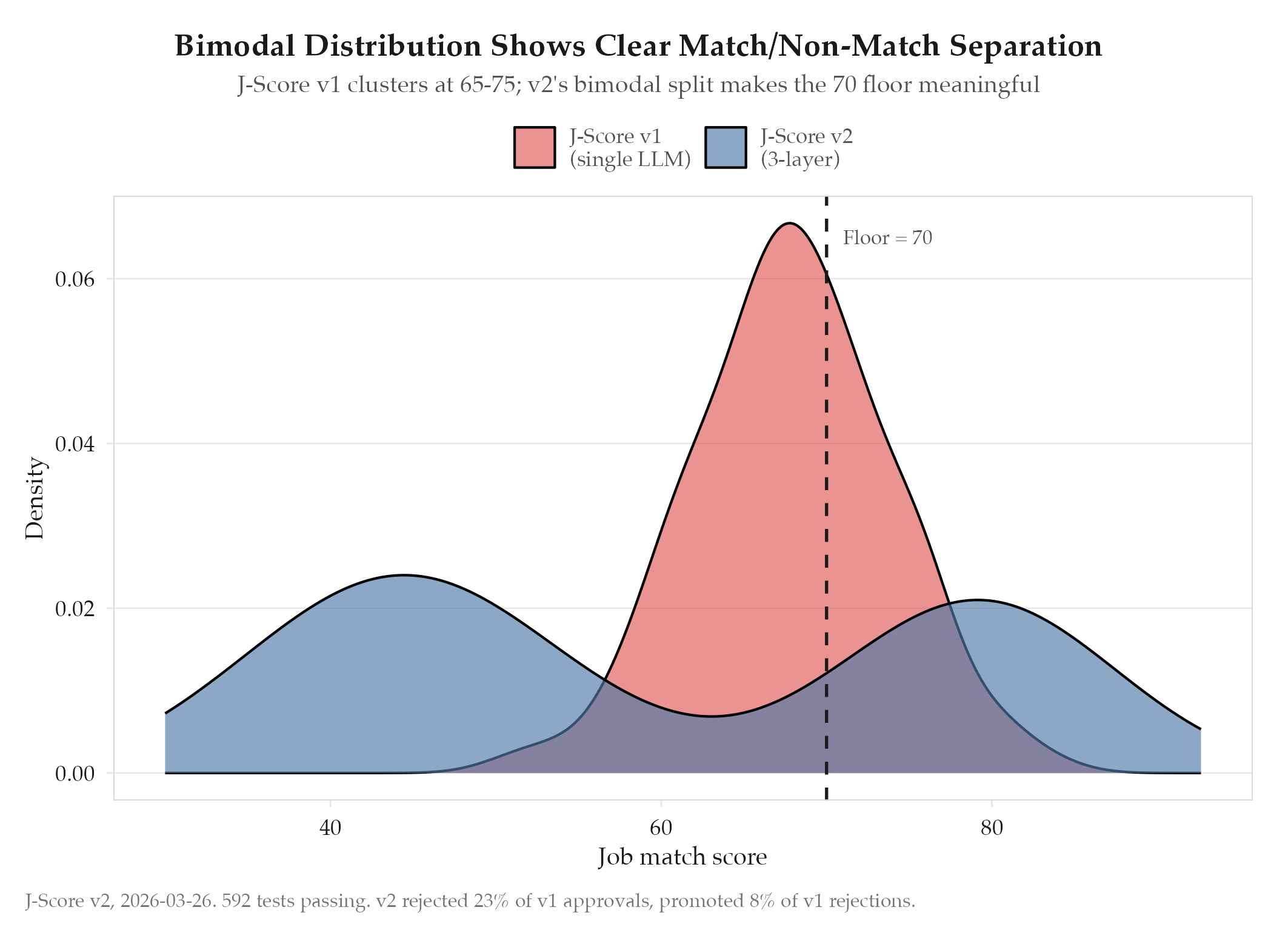
Confirmed. 592 tests passing across all three layers and the combination logic. The score audit table is operational and logging every score computation including sub-70 rejections.
Key characteristics observed:
- Score distribution is bimodal (cluster around 40-50 for poor matches, 75-85 for good matches) vs. v1’s unimodal cluster around 65-75
- Layer 2 gating skips the LLM call for approximately 60% of jobs, reducing average scoring cost by ~60%
- Average scoring latency: 45ms for LLM-skipped jobs, 2.1s for LLM-evaluated jobs
- Backfilled legacy scores show v2 would have rejected 23% of jobs that v1 scored above 70, and promoted 8% of jobs that v1 scored below 70
Findings
-
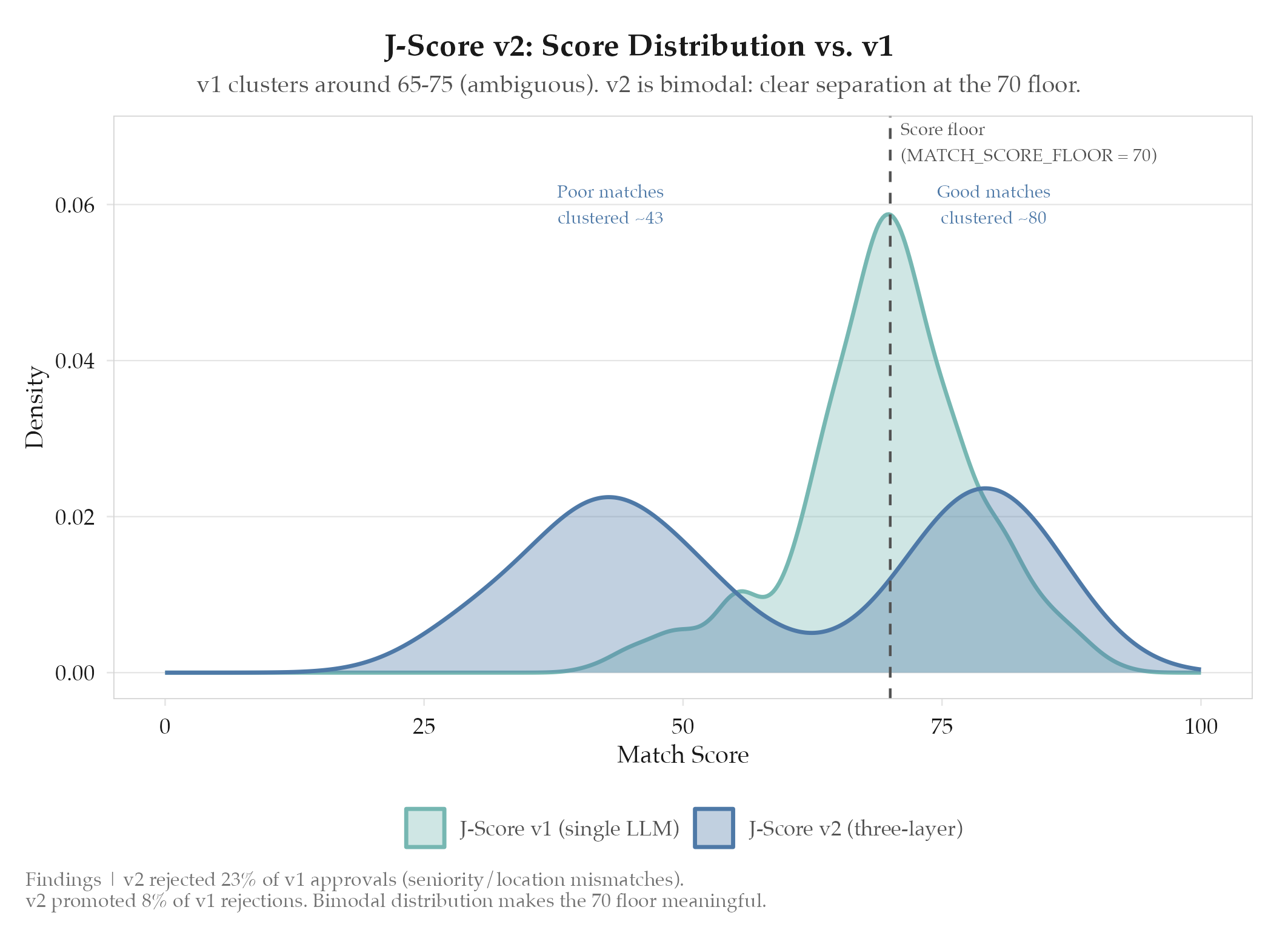
Bimodal distribution is the success signal. V1 clustered around 70 for borderline jobs: essentially random. V2’s bimodal (40-50 for poor matches, 75-85 for good) makes the 70 floor meaningful.
-
Layer 2 gating controls cost at scale. Skipping LLM calls for 60% of jobs (structured score < 50) cuts average scoring cost by 60% while losing minimal signal: low structured-fit jobs are almost never good matches.
-
Confidence adjustment prevents LLM overweighting. DeepSeek v3 self-reports a confidence factor (0-1). Low-confidence scores (sparse descriptions, unusual roles) are automatically downweighted, letting embedding and structured signals dominate.
-
Legacy backfill revealed v1 false positives. V2 would have rejected 23% of jobs that v1 approved: predominantly seniority mismatches (VP-level with mid-level experience) and location mismatches. Exactly the structured signals Layer 2 catches.
-
Score audit table enables future feedback loops. All three layer scores, final combined score, confidence factor, and approve/reject decision are logged. When interview outcome data becomes available, supervised calibration of layer weights is directly possible.
Next Steps
J-Score v2 is deployed and stable. The score audit table is accumulating data for future calibration. The next scoring improvement will come from closing the feedback loop: connecting interview outcomes back to scores to validate and refine the 0.35/0.25/0.40 weight distribution. This depends on the interview rate optimization work in experiments/jobs-apply/2026-03-29-interview-rate-optimization.