333 Applications, Zero Interviews
The most dangerous AI automation failure is not the crash you can see: it is the optimization loop that runs on the wrong metric. 155 commits, 272,202 net lines, and the week’s defining moment was zero lines of code: 333 job applications had vanished into silence because checkGmailResponses() existed in the codebase but was never called. The system had become very good at the thing that did not matter. From the data quality pipeline to Dakka’s terminal multiplexer, the same pattern recurred: invisible feedback loops masquerading as working systems.
The Feedback Loop That Didn’t Exist
The story starts with a crisis. On Monday, LinkedIn restricted the jobs-apply account after detecting 62+ applications submitted with sub-second delays, zero timing variation, and no scroll behavior: a statistical profile no human produces. The automation had optimized for speed, and speed is exactly what behavioral detection systems target.
Twenty-four hours later the account was back. But the restriction forced a complete rethink of what “good automation” means. The anti-detection suite that emerged became the week’s first breakthrough: 47 Gaussian timing points replacing uniform delays, 20-40 second reading simulations that scroll at human pace, Bezier mouse trajectories, and a 3-submissions-per-30-minute safety rail. By Sunday, Run 7 achieved 83% session success (5/6 attempts) with a click-and-verify loop that confirmed modal state after each interaction. The restriction was not a setback. It was the forcing function that made the automation production-grade.
Infrastructure followed. The multi-process coordinator (682 lines) gave each ATS platform its own isolated child process with exponential backoff restart (5s/10s/30s/60s). During the first overnight run, the LinkedIn worker crashed 14 times; Direct and Greenhouse kept flowing. The shadow DOM locator pitfall: Easy Apply’s modal rendering inside a closed shadow DOM inside a preload iframe: required CDP’s DOM.getDocument({ pierce: true }) for undetectable access.
The marketing side moved fast in parallel. A full marketing website shipped in 97 minutes on Tuesday: landing page, pricing, waitlist API, 2,626 lines, dark theme with scroll animations. The J-Score v2 pipeline replaced the monolithic LLM scorer with three layers: local semantic embeddings (22MB, ~30ms, $0/call), deterministic structured features (200+ skills, <1ms), and LLM evaluation gated at Layer 2 score > 50, cutting API costs by ~60% while 592 tests locked the interface. Smart Company Selection replaced the static Fortune 500 target list with database-backed priority scoring: 0.35 location fit, 0.25 remote friendliness, 0.25 staleness, 0.15 historical yield: and Direct channel held at 77.9% submission rate (113/145).
Everything was getting better. Applications were faster, smarter, more targeted, more human-looking. None of it mattered.
The interview rate optimization experiment: six subagents running a Karpathy ratchet on conversion rate: exposed the gap. Subagent 2 extracted 24 LinkedIn conversations. All 12 recruiter-originated messages were cold InMail from recruiters who had found the profile independently. Zero were responses to submitted applications. The interview rate from 333 applications: 0%.
The function checkGmailResponses() had existed since the module was written. It had tests. It had a clear interface. It was wired into absolutely nothing. The fix was a single import and function call at channel-run-loop.ts:604. Three hundred and thirty-three applications traveled through an optimization pipeline that measured submission success, timing distributions, modal interactions, and company targeting: everything except whether anybody wrote back.
This is the specific shape of the AI automation trap: you build a system that optimizes a proxy metric with such sophistication that the proxy metric’s improvement becomes indistinguishable from progress. Submission rate up. Detection avoidance up. Company targeting smarter. Application quality scoring running through three layers of ML. And behind all of it, a function that converts applications into actionable signal sitting in the codebase with zero callers.
The same pattern surfaced across three other projects during the week. The DQI evaluator had been measuring Pearson correlation against derived scores: a tautological metric where high-quality entries self-validate. The ratchet phase counter reset on every restart, making Phase 1 results look like progress through all phases. The IRI canonicalization script filtered at query time rather than application code, missing 73 entities on alternate integration paths. Meanwhile, the SessionEnd hook timeout silently killed the peon-notify flush at 1.5 seconds, meaning session manifests were never written: another feedback loop that looked functional because no error was reported.
Four broken feedback loops. Four systems that looked healthy. Four quiet catastrophes masquerading as normal operation. The quality of your automation is bounded by the quality of your feedback loop, and a missing feedback loop is the one failure mode that makes everything else look like it is working.
Transferable insight: Optimizing a proxy metric with sufficient sophistication makes improvement indistinguishable from progress. The failure mode is silent because nothing crashes: the system just never measures the thing that matters.
The Karpathy Ratchet
Mixin: DQI 0.9049 to 0.9790 across 6 ratchet sessions
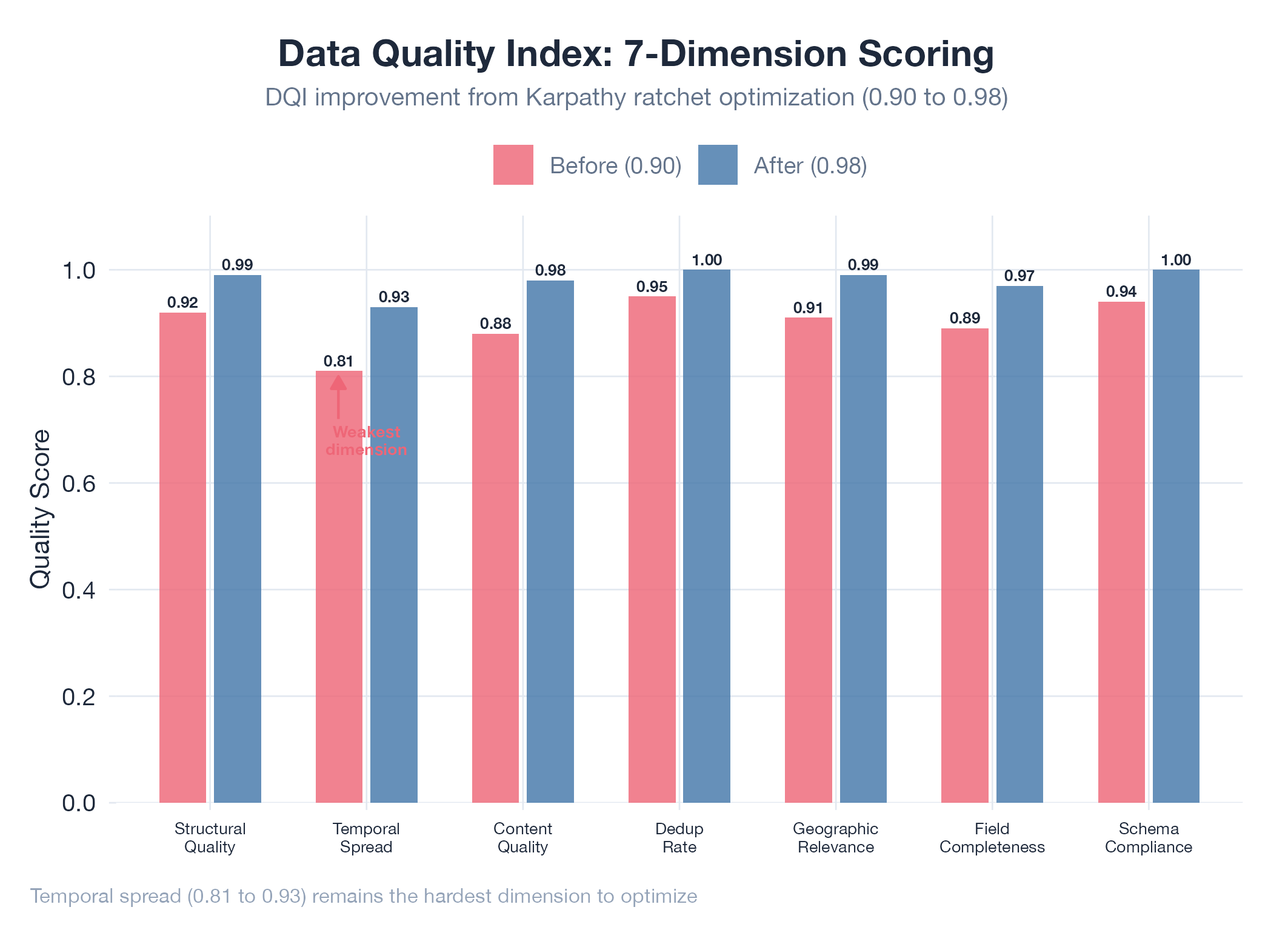
The Karpathy ratchet: systematic single-parameter iteration where only improvements survive: was designed for neural network training. This week proved it converges on data quality when the evaluator measures something real.
Monday’s first act was tearing down the old evaluator. DQI had been scoring against Pearson correlation on derived scores, a circular metric where the evaluator confirmed whatever the pipeline already believed. The rebuild replaced it with 6 objective verifiable properties: completeness, temporal accuracy, geographic relevance, description quality, source reliability, and structural validity. Baseline on the new evaluator: 0.9049.
Six ratchet sessions followed. The expansion horizon produced the largest combined gain: extending expansionHorizonDays from 90 to 360 added +0.025 DQI, and raising minDescriptionLength from 0 to 100 added +0.020. A 90-day horizon is blind to annual events: a class of data that simply does not exist in a shorter window. Sentiment calibration delivered the best single-experiment gain: lowering the positive threshold from 0.85 to 0.80 unblocked a population of good descriptions trapped in the 0.80-0.85 band (+0.000207 DQI). A secondary finding: neutral threshold 0.65 crashed the evaluator entirely: exposed a latent production bug that normal operations never triggered. Systematic parameter exploration doubles as adversarial testing. Pillar weight rebalancing confirmed optimal correctness weight at 0.50 (up from 0.40) while 14 follow-on richness and freshness experiments were all discarded. Sunday’s 20 threshold experiments also failed: gains come from structural changes to what you measure, not from adjusting where you draw the line.
The ratchet closed at temporalSpread = 0.8134, a config-level ceiling. The next improvement requires new event discovery sources, not better parameters.
Transferable insight: The Karpathy ratchet works for data quality, not just model training: but only if the evaluator measures objective properties rather than circular derivatives of its own output. Rebuild the evaluator first.
The Groundhog Day Bug
Mixin: Phase counter resetting to 0 on every restart
The ratchet ran six sessions, tested dozens of parameter combinations, and never reached Phase 3. Every session produced plausible results because Phase 1 and Phase 2 are reasonable starting points. The optimization appeared to make progress. It was running in place.
The root cause: the phase counter was a local variable initialized to 0 at process startup. Phase selection logic: “run Phase experimentCount % numPhases”: reset with every restart, and Phases 3 through 5 (geographic relevance, structural validation, source reliability) became dead code that compiled, had documentation, and never executed.
The fix was five lines: load experimentCount from the cumulative results.tsv at startup instead of initializing to zero. But the pattern generalizes. Any multi-phase optimization that stores progress in memory rather than on disk will silently regress to Phase 1 after a process restart. The outputs look reasonable because Phase 1 IS reasonable. The system does not crash, does not warn, does not fail a test. It just never advances, and “never advancing” looks exactly like “thoroughly exploring the early parameter space.”
This is the software equivalent of Groundhog Day: the system wakes up, runs Phase 1 competently, and has no memory that it has done this before.
Transferable insight: Any multi-phase optimization that stores phase progress in memory rather than on disk will silently regress to Phase 1 after every restart. The outputs look reasonable because Phase 1 IS reasonable: that is what makes it undetectable.
Zeitgeist
The AI agent ecosystem accelerated around autonomous verification during W13. Three signals from the timeline:
All three signals point the same direction: AI coding agents are crossing from generation into self-governance, and the tooling to make that work is arriving fast.
By the Numbers
| Metric | Value |
|---|---|
| Repositories | 4 |
| Commits | 155 |
| Net additions | 272,202 lines |
| Files changed | 1,116 |
| Largest single commit | +169,148 lines (feed-remediation pipeline + SERP mining) |
| Experiments | 17 (11 confirmed, 1 refuted, 5 inconclusive) |
| Breakthroughs | 6 |
| Pitfalls | 9 |
| DQI trajectory | 0.9049 to 0.9790 (+0.0741) |
| LinkedIn success | 0% to 83% (Run 6 to Run 7) |
| Applications without feedback | 333 |
Changelog
260507: v2 compliance update
Added title: to frontmatter. Stripped 9 private wikilinks (topics/, projects/, breakthroughs/, experiments/) to plain text. Added > **Transferable insight:** blocks to primary section and both mixins. Removed context-curator from projects_active. No content changes.
260506: Generated by journalize-weekly (topic-first format, proof article)
BLACKOUT week: no session data, no MQI trajectory, no cost table. All metrics derived from git summary (155 commits, 4 repos), daily journal entries (2026-03-23 through 2026-03-29), 17 experiment files, 6 breakthrough files, and 9 pitfall files from the packet. Topic-first format replaces project-by-project reporting: primary narrative (“333 Applications, Zero Interviews”), two mixin topics (“DQI Karpathy Ratchet”, “Ratchet Bug”), zeitgeist integration, compressed By the Numbers table.