333 applications, zero interviews: the feedback loop was never wired
2026-03-29
Signal
Running 333+ job applications and observing zero interview responses revealed that the outcome metric (interviews) was never wired to the feedback loop: the feedback signals existed in Gmail, but nothing was reading them, making the optimization loop structurally blind.
Evidence
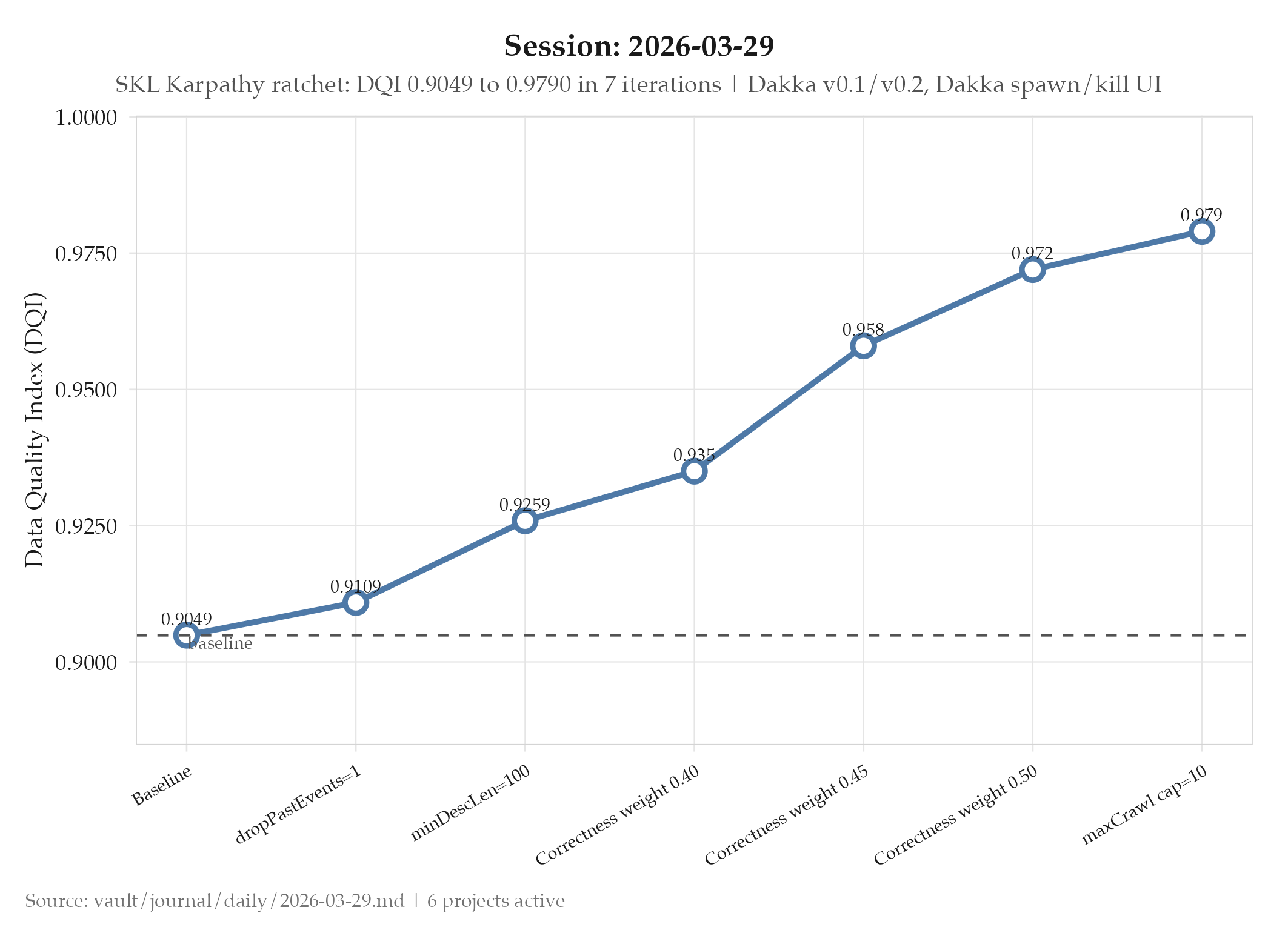
- Project: internal audit: DQI improved 0.9049 → 0.9790 across ratchet runs;
dropPastEvents=1(+0.006),minDescriptionLength=100(+0.015), correctness pillar raised 0.40 → 0.50;temporalSpread = 0.8134as remaining weakness; 2 pipeline fixes: 60s AbortController timeout, PDFmarkedconversion; bug fixed: ratchet phase selection used local counter not global count - Project: projects/jobs-apply/_index: Interview Rate Optimization: 333+ applications, zero interview visibility;
checkGmailResponses()wired intochannel-run-loop.ts:604; Subagents 1, 3, 4, 5, 6 Phase 1 complete; Smart Company Selection replaced static URL list with DB-backedCompaniesRepository.getNextBatch()with 4-factor priority scoring - Project: projects/dakka/_index: v0.1.0 (PTY management, XState, WebSocket protocol, xterm.js) + v0.2.0 (dynamic spawn/kill UI) built across 29 sessions
- Project: internal finance: 244-tool MCP server for QuickBooks Online; 31 code-review sessions
- Project: projects/bloomnet/_index: 17 code-review sessions continuing React dashboard development
So What (Why Should You Care)
The jobs-apply feedback loop finding is a systems design lesson with a specific mechanism. The pipeline was measuring the wrong thing: it counted applications submitted (activity metric) but had no signal on interviews received (outcome metric). Those are different measures of different things, and optimizing activity doesn’t improve outcomes if there’s no feedback path connecting them.
333+ applications went out. Zero interview signals came back. Not because there were no interview signals: they were in Gmail, arriving as recruiter emails. But nothing in the pipeline was reading them. The feedback mechanism existed in the world; it just wasn’t wired to the optimization loop. This is the machine learning equivalent of a gradient descent with a disconnected loss function: the system runs, produces outputs, but has no way to know whether those outputs are good or bad.
The fix (checkGmailResponses() wired into channel-run-loop.ts:604) closes this loop. Now when the system submits applications and receives responses, those responses flow back into the pipeline’s awareness. The system can now distinguish “applications that led to responses” from “applications that didn’t” and adjust accordingly. This is what self-correction requires: a feedback path from outcomes to the system that produced them.
The DQI improvement from 0.9049 to 0.9790 in internal audit today shows what happens when a feedback loop is working: each configuration change can be evaluated against a metric that reflects real quality. The Karpathy ratchet is a formalized feedback loop: each experiment produces a measurable outcome, and only improvements survive. The temporalSpread = 0.8134 ceiling shows where the loop reaches its limits: config-level optimizations are exhausted, and the next improvements require changing the data (new discovery sources), not the config.
projects/dakka/_index going from concept to v0.2.0 across 29 sessions in a single day demonstrates what’s possible when an architecture is clear from the start. PTY management, XState state machines, WebSocket protocol, xterm.js terminal UI, Electron shell, CLI, telemetry: each one is a bounded component. The spawn/kill UI in v0.2.0 is the interface layer on top of that foundation. Clear component boundaries let parallel development happen without coordination overhead.
What’s Next
- internal audit: address
temporalSpreadweakness (needs new discovery sources for Q4 2026+) - projects/jobs-apply/_index: Subagent 2 (LinkedIn message scanning) still pending; SaaS launch: 5 env var groups remain
- projects/dakka/_index: continue v0.3.0 development
Log
- internal audit: Karpathy Ratchet major progress: DQI 0.9049 → 0.9790
dropPastEvents=1: removed ~1,400 past events, DQI +0.006minDescriptionLength=100: removed short/no-desc events, DQI +0.015- Correctness pillar weight raised 0.40 → 0.50 across 4 commits
maxCrawlCandidatesPerPlacecapped at 10 (field enforcement phase 5)- 2 pipeline fixes: 60s AbortController timeout + header forwarding; PDF
markedconversion - Bug fixed: ratchet phase selection used local counter instead of global experiment count from results.tsv
- Remaining weakness:
temporalSpread = 0.8134: config-level optimizations exhausted - projects/jobs-apply/_index: Interview Rate Optimization launched: 6 subagents
- 333+ applications submitted; zero interview visibility: feedback loop was unwired
checkGmailResponses()wired intochannel-run-loop.ts:604scripts/interview-scan.tswritesscore_audit.outcomechannel-interview-report.tsupdatesanalytics.interviewsScheduled- Subagents 1 (Email cross-ref), 3 (Channel attribution), 4 (J-Score correlation), 5 (Website funnel), 6 (Experiment migration) Phase 1 complete
- Smart Company Selection: replaced static Fortune 500 list with DB-backed
CompaniesRepository.getNextBatch() - Priority score: 0.35×location + 0.25×remote + 0.25×staleness + 0.15×yield
- Cross-channel learning across all job sources
- projects/dakka/_index: v0.1.0 + v0.2.0 across 29 sessions
- v0.1.0: PTY management, XState state machines, WebSocket protocol, xterm.js terminal UI, Electron shell, CLI, telemetry, spores
- v0.2.0: Dynamic spawn/kill UI (+/- buttons), fixed spawn order, CLAUDE.md
- internal finance: 244-tool MCP server for QuickBooks Online; 31 code-review sessions
- projects/bloomnet/_index: 17 code-review sessions continuing React dashboard development
- Additional jobs-apply work: Easy-apply form filling, LinkedIn social listening agent, PeonNotify memory leak audit, GitHub Actions CI/CD verification