Knowledge Graph
Connecting facts as a web of relationships, not rows in a table. Entities linked by meaning.
A knowledge graph stores facts as a web of typed connections: Eiffel Tower -[located_in]→ Paris -[located_in]→ France. Every fact is a subject-predicate-object triple, and every triple can be traversed. This beats flat tables when relationships are first-class data : enabling multi-hop queries (“what events are happening within 50km of a UNESCO site?”), entity resolution (recognizing that “NYC” and “The Big Apple” are the same node), and inference (if A is_part_of B and B is_in C, then A is_in C). Standards: RDF for triples, SPARQL for querying.
How It Works
Three building blocks: entities (nodes), relationships (typed edges), properties (attributes on nodes). Graph databases like Neo4j or triple stores optimize for traversal queries that relational databases handle poorly.
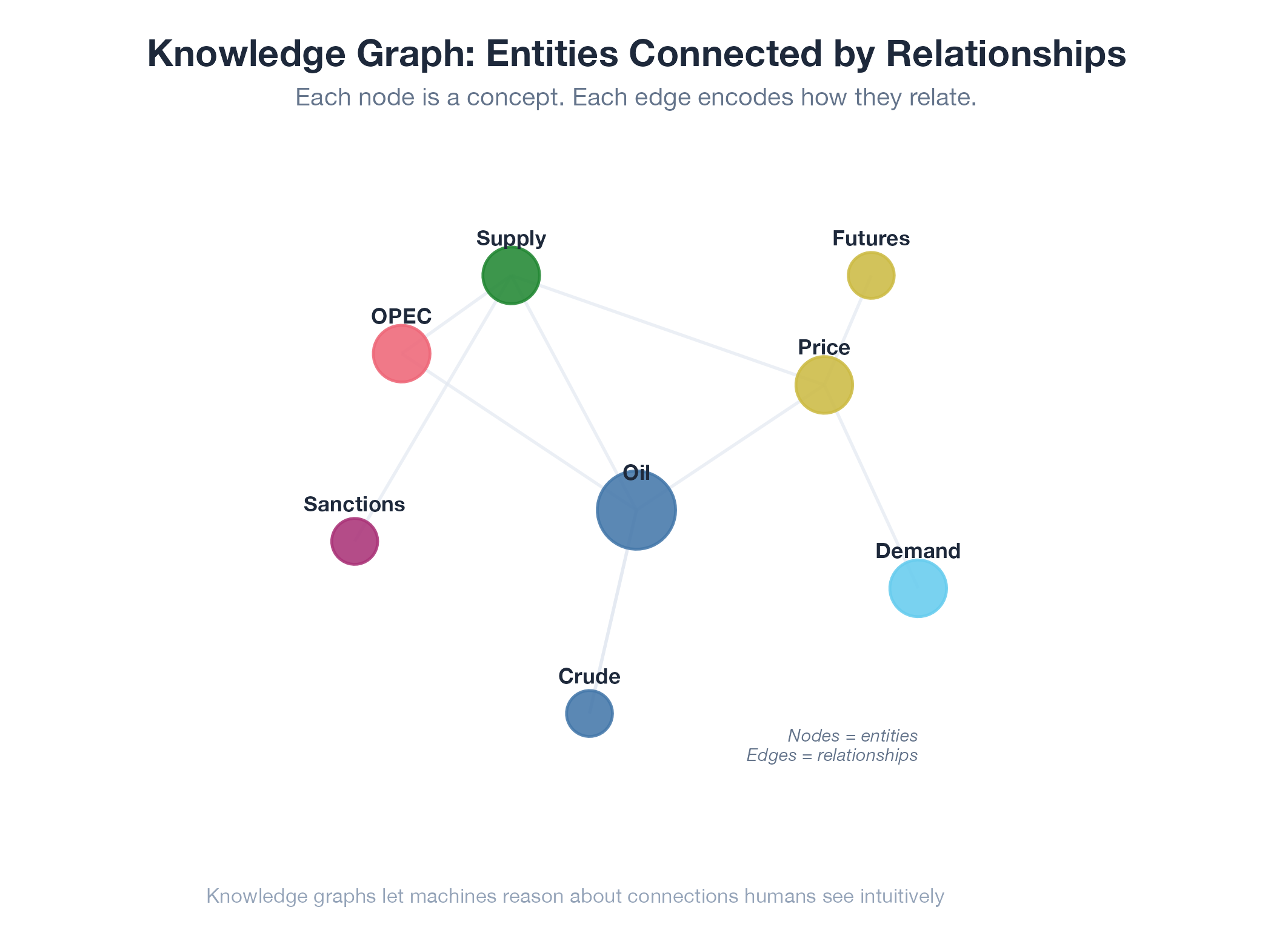
Example
A knowledge graph for event discovery connects events, venues, organizations, and locations as typed nodes. Entity deduplication is a core challenge: the same festival might appear under three names from three sources. IRI canonicalization and deduplicated entity groups resolve these into single nodes. DQI penalizes orphan nodes with no relationships : completeness requires not just data, but connected data.