ETL Pipeline
Extract-Transform-Load pattern for moving and reshaping data between systems.
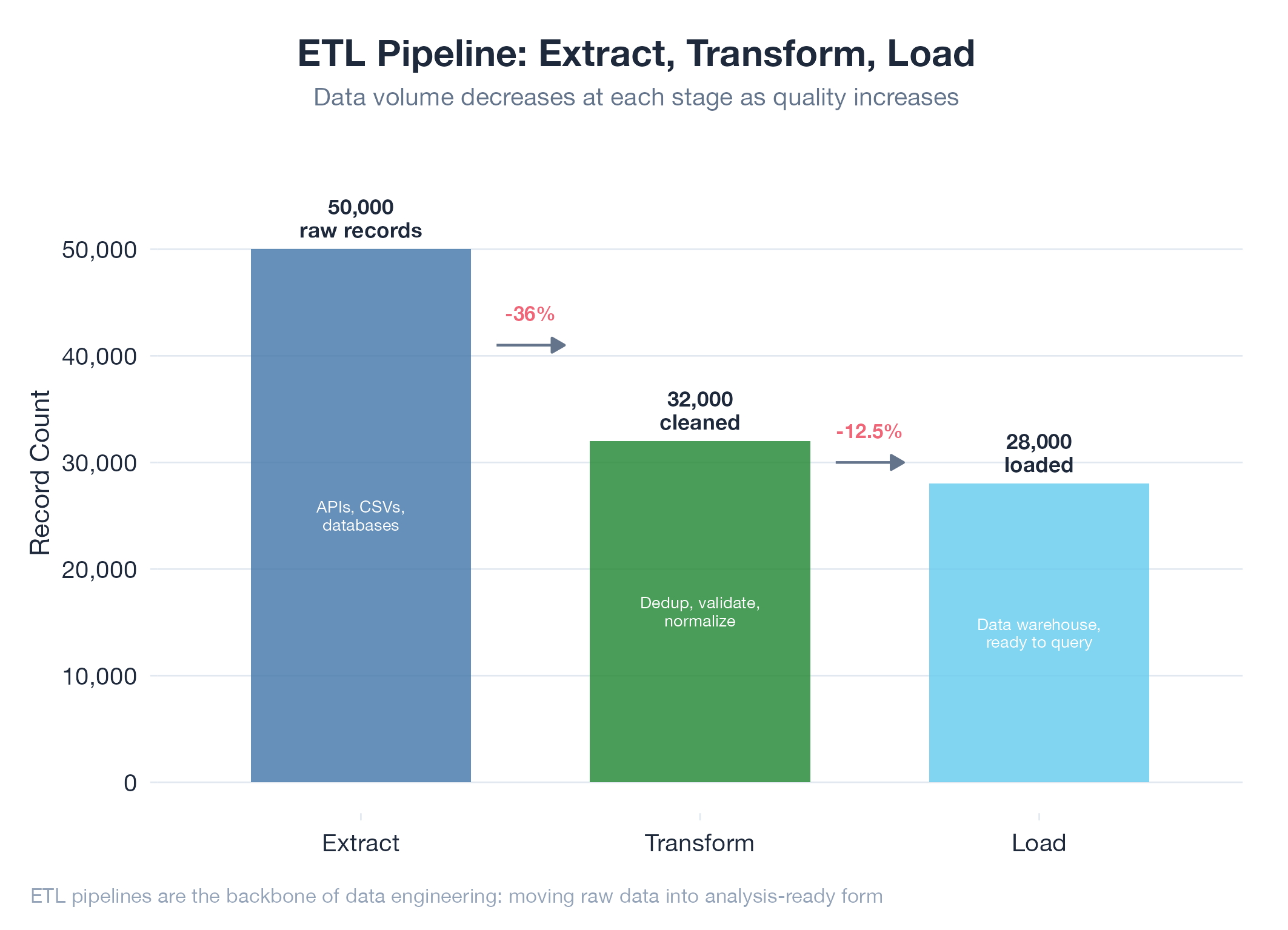
ETL (Extract, Transform, Load) is the foundational pattern for moving data from where it lives to where it needs to be. Extract pulls raw data from sources (APIs, databases, web pages). Transform cleans, enriches, and reshapes it. Load writes the result to a destination. Modern pipelines add sophistication: DAG-based execution orders stages by declared dependencies, content hashing prevents reprocessing unchanged records, and quality gates stop bad data from propagating downstream. Every application that consumes external data has an ETL pipeline, whether or not it’s called one.
How It Works
Three stages run in order. Extract is I/O-bound (network calls, scraping). Transform is CPU-bound (validation, enrichment, scoring). Load is often idempotent (upsert by ID). Content-hash deduplication makes the whole pipeline restartable without side effects.
Example
The jobs-apply Gmail crawl pipeline is a 3-layer ETL: ingestion (IMAP fetch of raw emails) to classification (AI categorizes each email as interview, rejection, or other) to state update (matches emails to applications, advances the state machine). Content hash dedup prevents reprocessing unchanged messages.