Structured feature gate eliminates 60% of LLM calls while improving quality
2026-03-26
Signal
Gating the expensive LLM scorer behind a structured features layer that must score above 50 eliminated approximately 60% of API calls while simultaneously improving match quality: because low-structure matches that skip the LLM evaluation are almost always correctly identified as poor matches by the structure layer anyway.
Evidence
- Project: projects/jobs-apply/_index: J-Score v2 deployed; replaced legacy bag-of-words + single LLM scorer that had 17 documented weaknesses
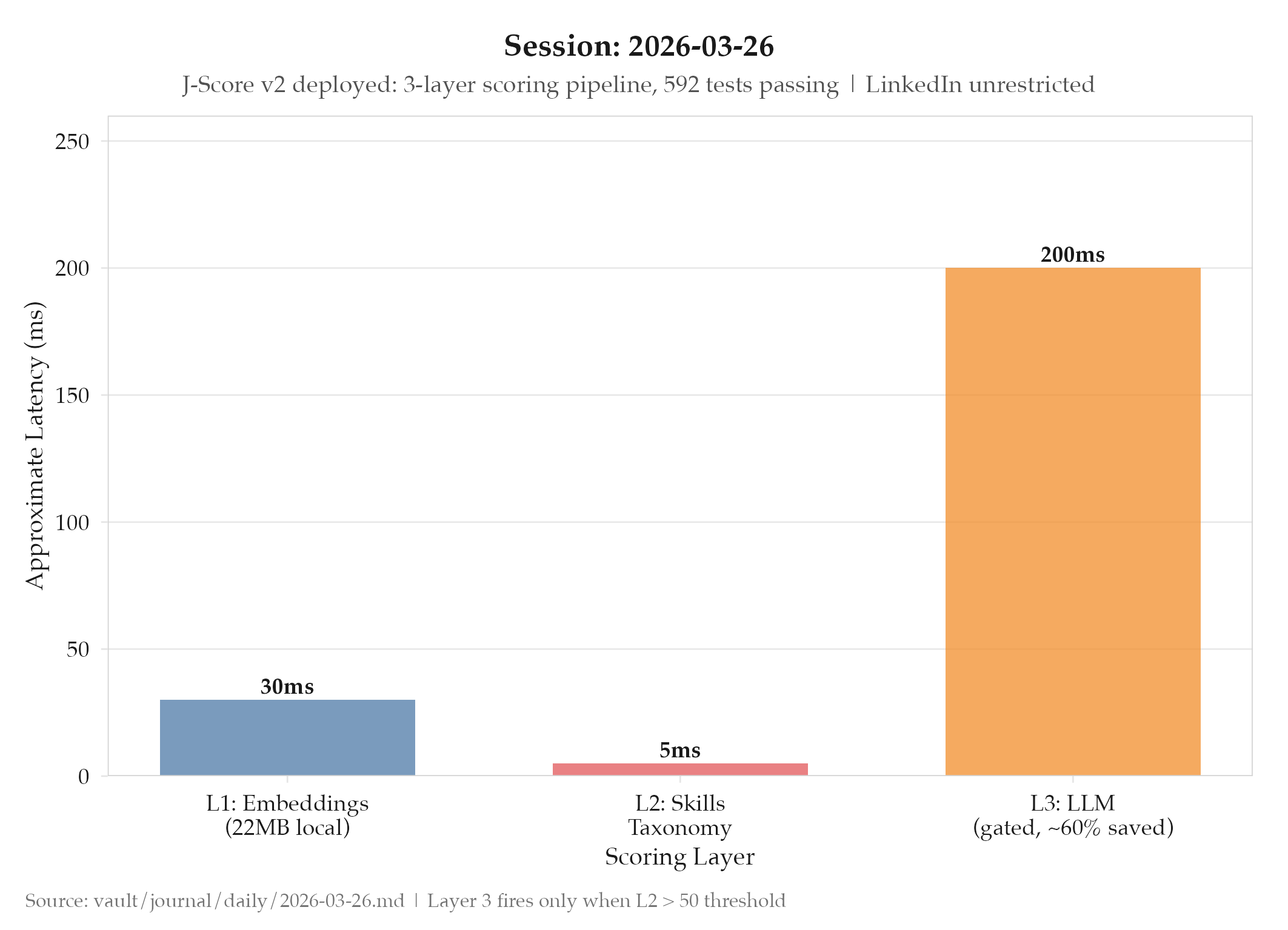
- Layer 1: Semantic embeddings: Xenova/all-MiniLM-L6-v2 (22MB local model, ~30ms per text), runs on every candidate
- Layer 2: Structured features: skills taxonomy with 10 categories and 200+ skills; deterministic and auditable
- Layer 3: LLM scorer: gated: only runs if Layer 2 score > 50; ~60% of candidates filtered before reaching this layer
- Logging: ALL scores logged including rejections: every candidate that didn’t reach Layer 3 is recorded for future calibration
- Test coverage: 592 tests passing
- LinkedIn restriction lifted: account unrestricted at 4 PM PDT as expected; all P0 remediation measures from 2026-03-25 now active
So What (Why Should You Care)
The J-Score v2 architecture is a template for any system that combines fast semantic search with expensive LLM evaluation. The key insight is that the three layers aren’t just doing the same task with different accuracy: they’re doing different tasks that complement each other.
Layer 1 (embeddings) answers: “Is there any semantic similarity at all?” It’s cheap (30ms, local, no API cost) and catches the obvious mismatches. A data engineer posting doesn’t need LLM evaluation to know it’s not a strong match for a backend platform engineering role.
Layer 2 (structured features) answers: “Does the candidate have the specific skills this job requires?” It’s deterministic: you can audit exactly why a score was what it was. A job requiring Kubernetes, Terraform, and Go that maps to none of the candidate’s 200+ tracked skills produces a low structured score with a clear reason.
Layer 3 (LLM) answers: “Given everything we know, how well does this candidate actually fit?” This is the expensive, high-value question: but it only needs to be asked when layers 1 and 2 have already established that the candidate is plausibly qualified. By the time a candidate reaches Layer 3, they’ve passed two cheaper filters that confirm basic semantic overlap and skill match. The LLM gets to focus on the nuanced evaluation that machines are good at: understanding how a candidate’s experience narrative maps to a job’s actual responsibilities.
The 60% cost reduction isn’t just about money: it means the LLM layer sees higher-quality input and produces better-calibrated scores.
Logging ALL scores including rejections is a decision that pays dividends later. Today’s rejected candidates: the ones that didn’t pass Layer 2 and never reached the LLM: are tomorrow’s calibration data. If you look at them in 30 days and find that the Layer 2 gate was rejecting candidates who actually got interviews, that’s signal that the Layer 2 structured features scoring needs calibration. Without the rejection log, you can never audit whether the gate is calibrated correctly.
The 592 tests passing across a three-layer scoring system represents a meaningful coverage depth. Layer 1 embedding tests verify that semantically similar texts produce similar scores. Layer 2 structured feature tests verify that specific skills in a job description are correctly matched against the candidate’s skill inventory. Layer 3 LLM tests verify that the prompt produces consistent, well-calibrated output for known good and known bad matches. Each layer needs its own test strategy because each layer has a different failure mode.
The confidence-weighted score fusion is also worth understanding mechanically. Rather than averaging scores from the three layers equally, each score is weighted by the layer’s confidence in that score. If Layer 1 (semantic embeddings) has high confidence for a particular text pair, its score gets more weight in the fusion. If it has low confidence (the embeddings are near the decision boundary), its score gets less weight. This means the system degrades gracefully: when one layer is uncertain, the other layers carry more of the signal.
The LinkedIn restriction lifting at the exact predicted time (4
PM PDT) with all P0 remediation measures ready validates the remediation plan design. The restrictions expired as LinkedIn stated they would. The measures were in place before the restriction lifted. The first fully-remediated run can begin.What’s Next
- Monitor J-Score v2 match quality vs. historical legacy scores via calibration log
- Run LinkedIn with all P0 remediation measures active: first fully remediated run
Log
- projects/jobs-apply/_index: J-Score v2 deployed: replaced legacy bag-of-words + single LLM scorer
- 17 documented weaknesses in legacy scorer addressed
- Layer 1: Xenova/all-MiniLM-L6-v2 semantic embeddings (22MB local, ~30ms/text)
- Layer 2: structured features: skills taxonomy with 10 categories, 200+ skills; deterministic
- Layer 3: LLM gated by Layer 2 score > 50: ~60% API cost savings
- Confidence-weighted score fusion across all three layers
- ALL scores logged including rejections for future calibration
- 592 tests passing
- LinkedIn account unrestricted at 4 PM PDT: all P0 remediation measures active