Gating AI calls behind deterministic pre-scoring eliminates 88% of wasted spend
2026-03-17
Signal
At $60.78/week for AI scoring with only 347 of 2,860 entities passing a quality threshold, the real optimization wasn’t better scoring: it was gating AI calls behind deterministic pre-scoring to eliminate the 87.9% of entities that would obviously fail.
Evidence
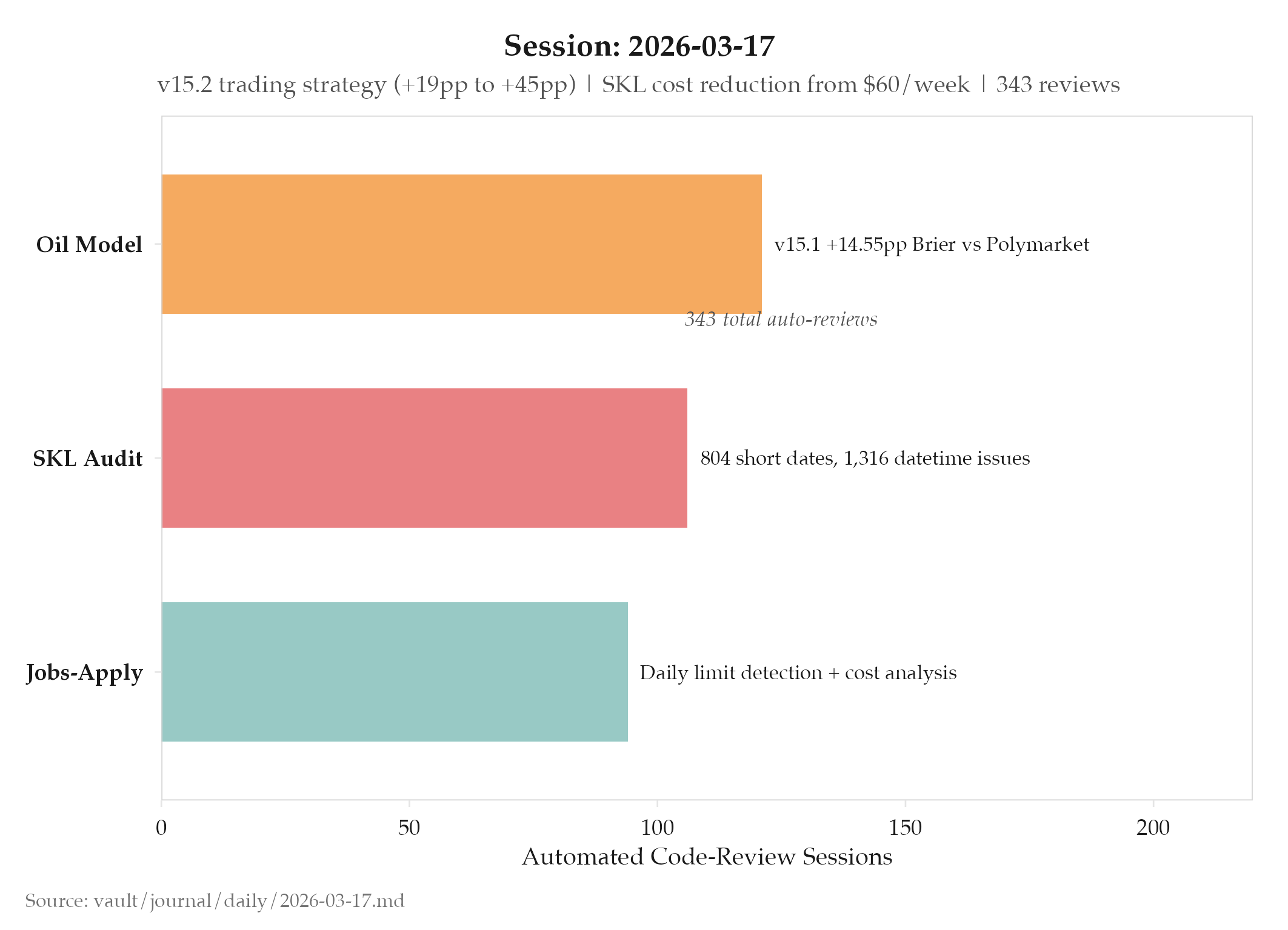
- Project: internal audit: AI Scoring Cost Reduction: $60.78/week with only 347/2,860 entities passing (12.1% pass rate)
- Solution: Deterministic pre-scoring gates AI calls: entities that can’t possibly pass don’t reach the AI scorer
- Also: Event DateTime Audit: 804 short dates and 1,316 datetime issues found; timezone-aware parsing and normalization pipeline built
- Project: projects/oil/_index: v15.1 Quant-Grade Model Validation: +14.55pp Brier advantage over Polymarket, 20-year quant audit; v15.2 Trading Strategy with 6 thresholds (+19pp to +45pp advantage range)
- Project: projects/jobs-apply/_index: Robust daily limit detection → automatic worker pause; lifetime project cost audit; failed job queue clearing fix
- Volume: 343 automated code-review sessions (oil: 121, internal audit pipeline: 106, jobs-apply: 94)
So What (Why Should You Care)
The cost problem in internal audit is a textbook case of why tiered validation architectures exist. Running a $0.02 AI call on every entity when 88% will fail wastes $52.86 per week on calls that produce nothing useful. At scale: $60/week: that’s $3,120 per year spent scoring entities that deterministic checks could have rejected for free in milliseconds.
The fix isn’t a better AI model. The AI model is fine at what it does: evaluating entities that are plausibly in-scope. The fix is not calling it for entities that a deterministic check can eliminate without any AI involvement at all. This is the difference between optimizing the expensive step and eliminating the need for the expensive step in most cases.
The principle transfers directly. Any system with an expensive operation: an LLM call, an external API request, a database write, a cloud function invocation: should gate that operation behind cheap, local checks first. Check the input schema before calling the API. Check the cache before querying the database. Check the deterministic quality criteria before invoking the LLM. The goal is that the expensive step only sees input where its cost is justified by the value of its output.
The 804 short dates and 1,316 datetime issues found in the Event DateTime Audit reflect a different kind of quality gap. DateTime normalization is infrastructure work: it doesn’t directly improve the quality scores, but it’s a prerequisite for any temporal quality metric being reliable. Timezone-aware parsing matters because “7pm” in Atlanta is different from “7pm” in San Francisco, and a system that doesn’t account for that will produce incorrect freshness and scheduling accuracy scores for multi-timezone event data.
The Brier score advantage on the oil model (+14.55pp over Polymarket) is worth unpacking. A Brier score measures probability calibration: not just whether your predictions are directionally correct, but whether your confidence levels match reality. +14.55pp means the model isn’t just more accurate; it’s better calibrated. That matters for any use case where you’re acting on probabilities rather than binary yes/no predictions.
What’s Next
- Monitor cost impact after deterministic pre-scoring deployment
- Validate Event DateTime normalization pipeline against production data
Log
- internal audit: AI Scoring Cost Reduction analysis: $60.78/week with 347/2,860 entities passing (12.1%)
- Implemented deterministic pre-scoring gate: AI scorer only sees entities that can pass basic checks
- Event DateTime Audit: 804 short dates, 1,316 datetime issues found
- Built timezone-aware date parsing and normalization pipeline
- Key decision: deterministic pre-scoring before AI to cut costs and improve signal quality
- projects/oil/_index: v15.1 Quant-Grade Model Validation
- +14.55pp Brier score advantage over Polymarket
- 20-year quant audit completed
- v15.2 Trading Strategy: 6 thresholds, +19pp to +45pp advantage range
- projects/jobs-apply/_index: robust daily limit detection → automatic worker pause
- Audited lifetime project costs (not just past week)
- Fixed failed job queue clearing bug
- 343 automated code-review sessions (oil: 121, internal audit pipeline: 106, jobs-apply: 94)