Rate Limiting
Controlling how fast you can make requests. A bouncer for APIs that prevents overload and abuse.
Controlling how fast you can make requests. A bouncer for APIs that prevents overload and abuse.
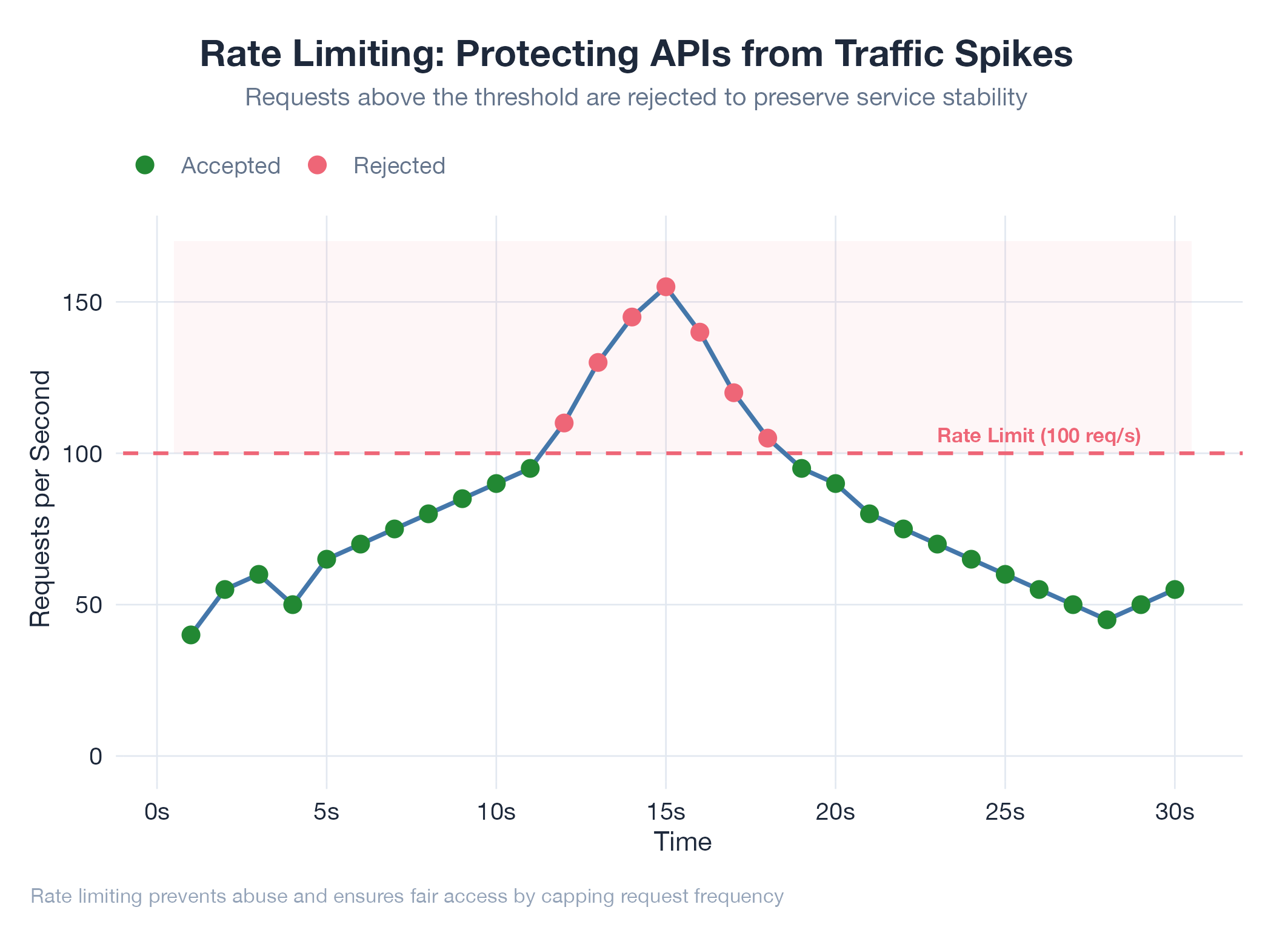
Rate limiting controls how many requests a client can make in a given time window: the bouncer that matches traffic to server capacity. Hit the limit and you get a 429 Too Many Requests response with a Retry-After header. Common strategies: fixed window (100 req/min, simple but bursty), sliding window (smooths burst abuse), and token bucket (allows burst up to bucket size while enforcing an average rate). Limits can apply per user, per API key, per IP, or per endpoint. Premium tiers typically get higher limits.
How It Works
Server tracks request counts per key/window → rejects with 429 when exceeded → exposes X-RateLimit-Remaining and X-RateLimit-Reset headers so clients can self-throttle before hitting the wall.
Example
Dakka’s orchestrator reads Anthropic API rate limit headers (X-RateLimit-Remaining) in real time, displaying remaining capacity as live progress bars in the usage monitoring UI. This lets you throttle agents proactively before hard limits trigger. Jobs-apply must respect rate limits across LinkedIn, Greenhouse, Lever, Workday, and the Anthropic API simultaneously. Architecture at Dakka.