Progressive Deployment
Deploy, measure breakage, fix, deploy again. Each iteration hardens the system through real-world contact.
Deploy, measure breakage, fix, deploy again. Each iteration hardens the system through real-world contact.
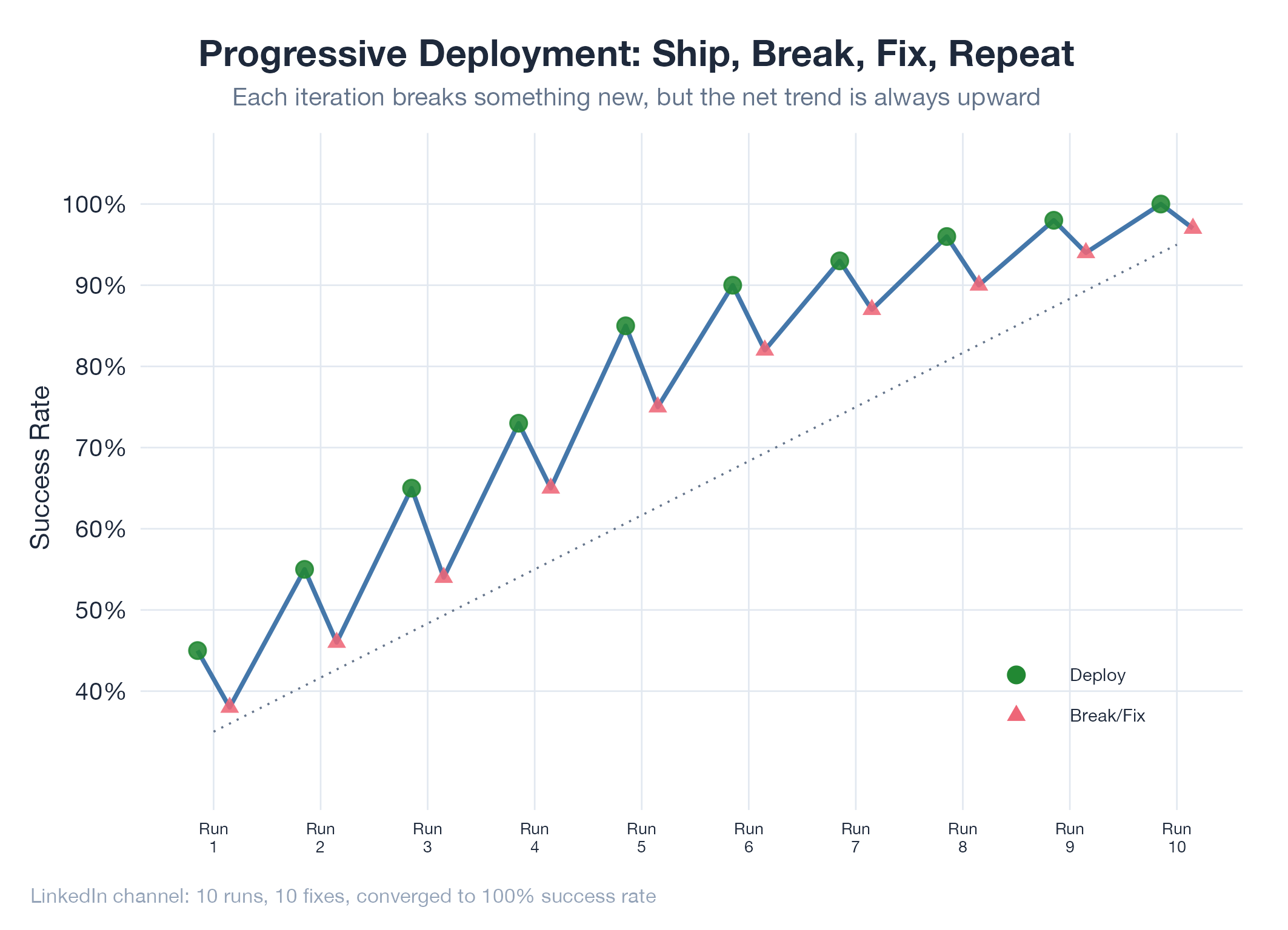
Progressive deployment ships to production early and often, treating each deployment as a controlled experiment. The system breaks in ways you didn’t predict. You fix those breaks. You ship again. After ten rounds, you have a system stress-tested by reality, not imagination. The critical insight: each iteration doesn’t just fix bugs: it makes the system structurally more resilient. Run 1 teaches you about timeouts. Run 3 reveals race conditions. Run 7 surfaces state corruption. By Run 10, the system has absorbed the lessons of all previous failures.
How It Works
Deploy → measure (success rates, error types, timing) → diagnose root causes → fix and harden → repeat. Requires monitoring to distinguish signal from noise. Avoid when failures are catastrophic and irreversible.
Example
LinkedIn Runs 1–10 are the canonical example. Run 1 had 0% submission rate. Each run surfaced a new failure class: Run 3 scroll-loading, Run 5 CDP select blur, Run 7 hydration timing. By Run 10 every failure mode was addressed and the submission rate hit 100%. Plan at Jobs Apply LinkedIn Remediation.