LLM Agent Architecture
Design patterns for autonomous AI agents that use tools, memory, and planning.
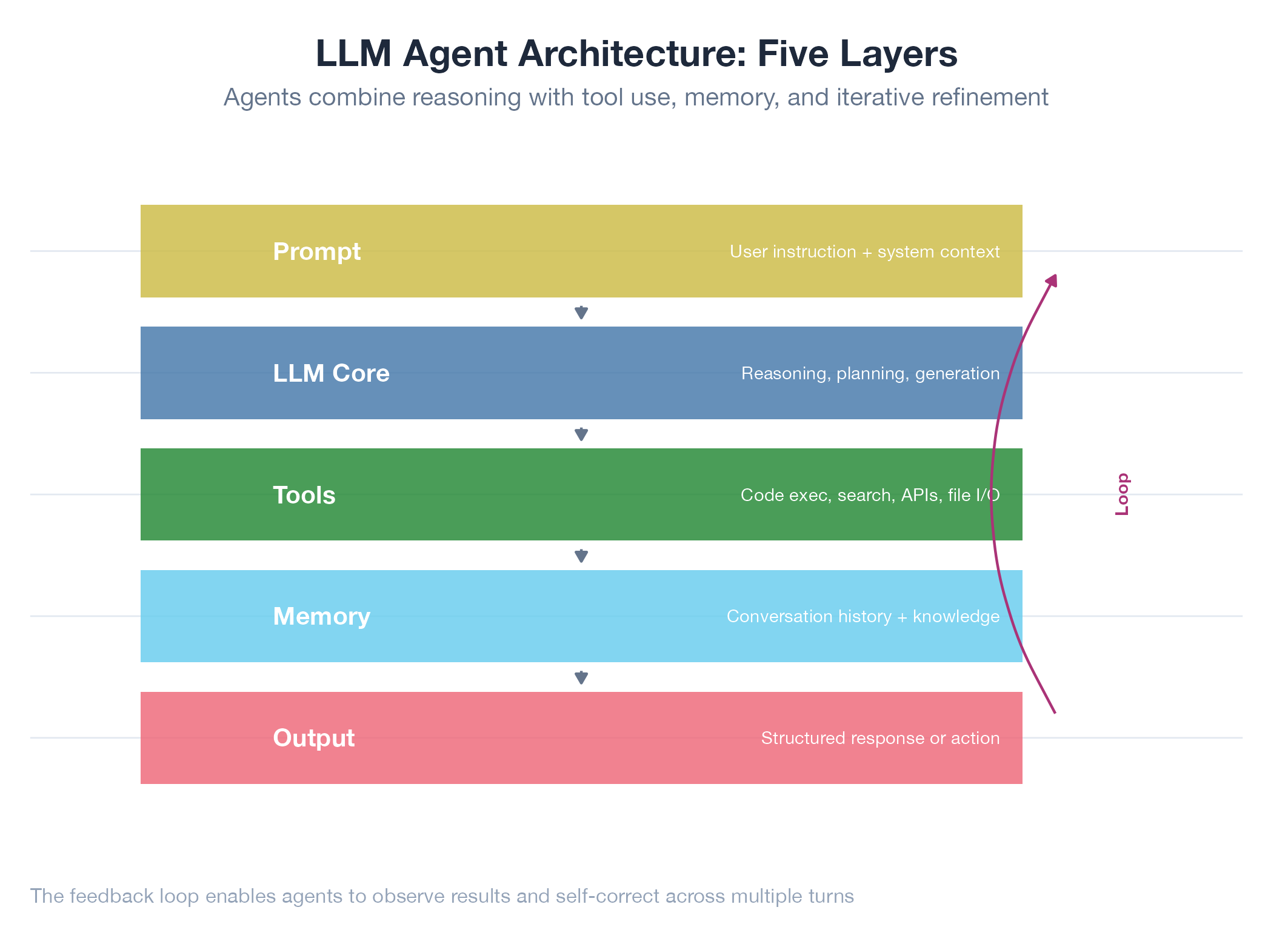
An LLM agent is a language model that takes actions, not just answers questions. Given a goal, it decides which tools to call, interprets results, updates its plan, and repeats until done. The architecture has four layers: tool use (structured function calls the harness executes), memory (short-term context + optional long-term knowledge store), planning (goal decomposition, progress tracking, replanning on failure), and multi-agent coordination (role assignment and communication between specialized agents). The shift from “LLM as chat” to “LLM as agent” transforms a knowledge retrieval tool into an autonomous system.
How It Works
The model emits a tool call → harness executes it → result goes back into context → model decides the next action. Loops until the goal is met or the model declares it cannot proceed.
Example
Dakka orchestrates parallel Claude Code sessions with 4 specialized roles (mekboy, weirdboy, kommando, painboy) communicating via WebSocket. The Rust migration (rusty-dakka) built 607+ tests across this architecture. Jobs-apply uses 6 platform agents each with its own Chrome process and behavior profile. Architecture overview at Dakka.