J-Score v2: three-layer fusion scoring, score clustering eliminated
Single-layer LLM scoring (Gemini Flash), scores clustered 65-75 regardless of actual fit -> Three-layer fusion scoring, 592 tests, 3742 backfilled scores, score audit logging, full score distribution
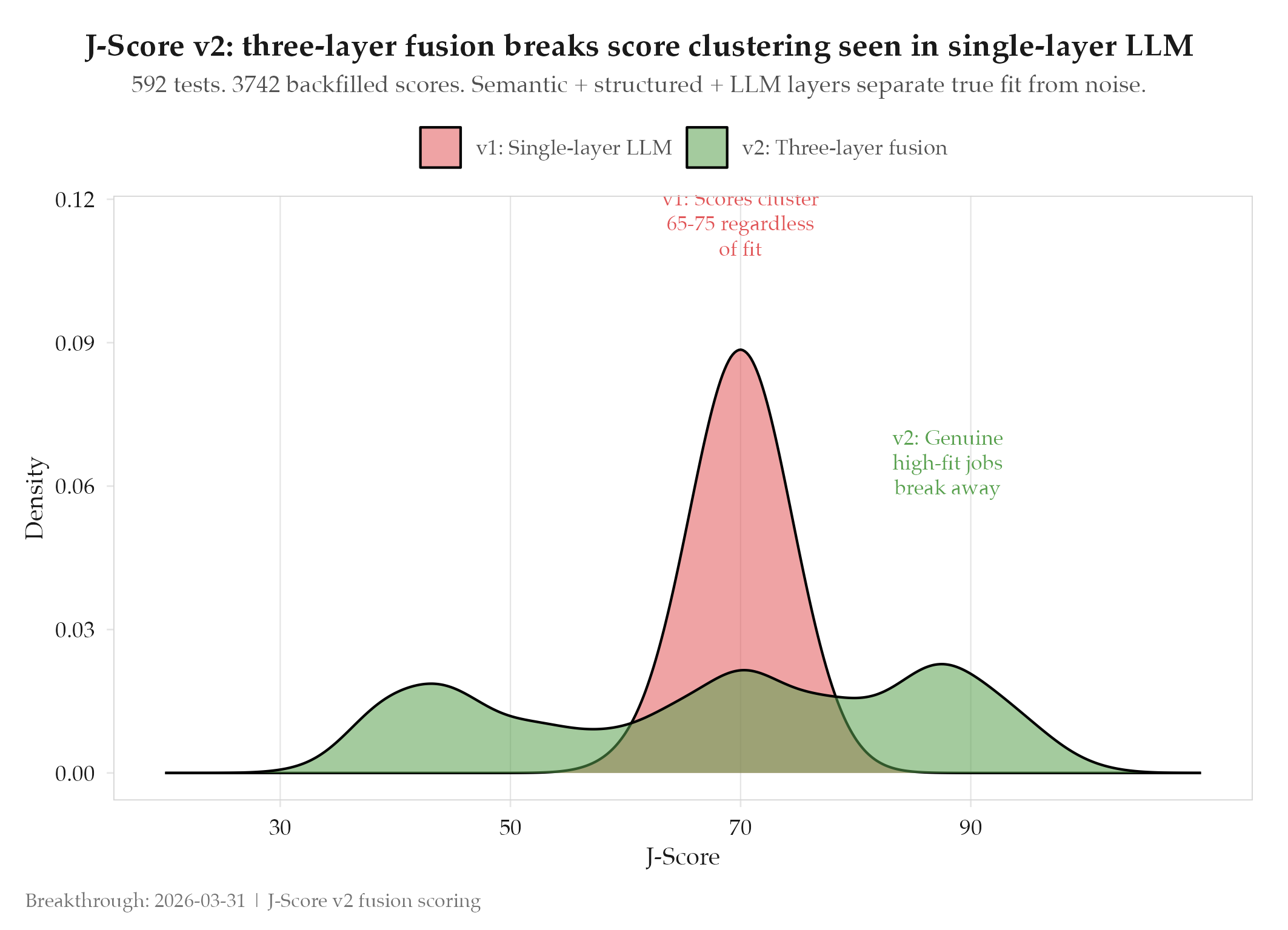
Single-layer LLM scoring gives every job a score between 65 and 75. That’s not scoring: it’s statistical noise. J-Score v2 replaced it with a three-layer fusion architecture that actually discriminates between strong matches and weak ones.
Context
The original job matching system used a single Gemini Flash call to score candidate-job fit on a 0-100 scale. The problem: LLMs tend to cluster scores in the middle of the range regardless of actual fit quality. A remote data analyst role in San Francisco and a local junior analyst role in the candidate’s city might both score 71. The system couldn’t distinguish genuinely strong matches from marginally acceptable ones. Applications were being submitted without reliable prioritization.
3742 jobs had been scored with the old system and needed re-evaluation. The backfill was only feasible if the new scoring pipeline was architecturally sound and fast enough to process at scale.
What Changed
J-Score v2 uses three independent layers that each contribute a different dimension of fit signal:
Layer 1: semantic embeddings: fast cosine similarity between job description and resume embeddings. Provides an initial fit signal in milliseconds without an LLM call. Used for pre-filtering.
Layer 2: structured features: hard-requirement matching for location, experience level, required skills, and compensation. Binary signals that the LLM often ignores or underweights. A job requiring 8 years of experience cannot be a strong match for a 3-year candidate regardless of how well the descriptions match.
Layer 3: enhanced LLM: Gemini Flash with structured prompting calibrated to use the full 0-100 range. The prompt explicitly instructs the model to distinguish between 70 (acceptable) and 90 (strong match) and 50 (weak match). The structured features from Layer 2 are injected as constraints.
A score audit table logs every score with its contributing factors, enabling feedback loop training as interview outcomes accumulate.
Impact
Before: scores clustered 65-75 for virtually every job. No discrimination between strong and weak matches. After: 592 tests validating the scoring pipeline. 3742 jobs re-scored with full score distribution. Score audit table live.
The score audit table is the forward-looking value: as interview outcomes accumulate, the scoring model can be calibrated against real results. This turns J-Score v2 from a static model into a learning system.
Source
- Skill: skills/j-score-v2-matching
- Experiment: experiments/jobs-apply/2026-03-26-jscore-v2-scoring
- Project: projects/jobs-apply/_index