Cascade attack: multi-turn > single-turn for AI safety red-teaming
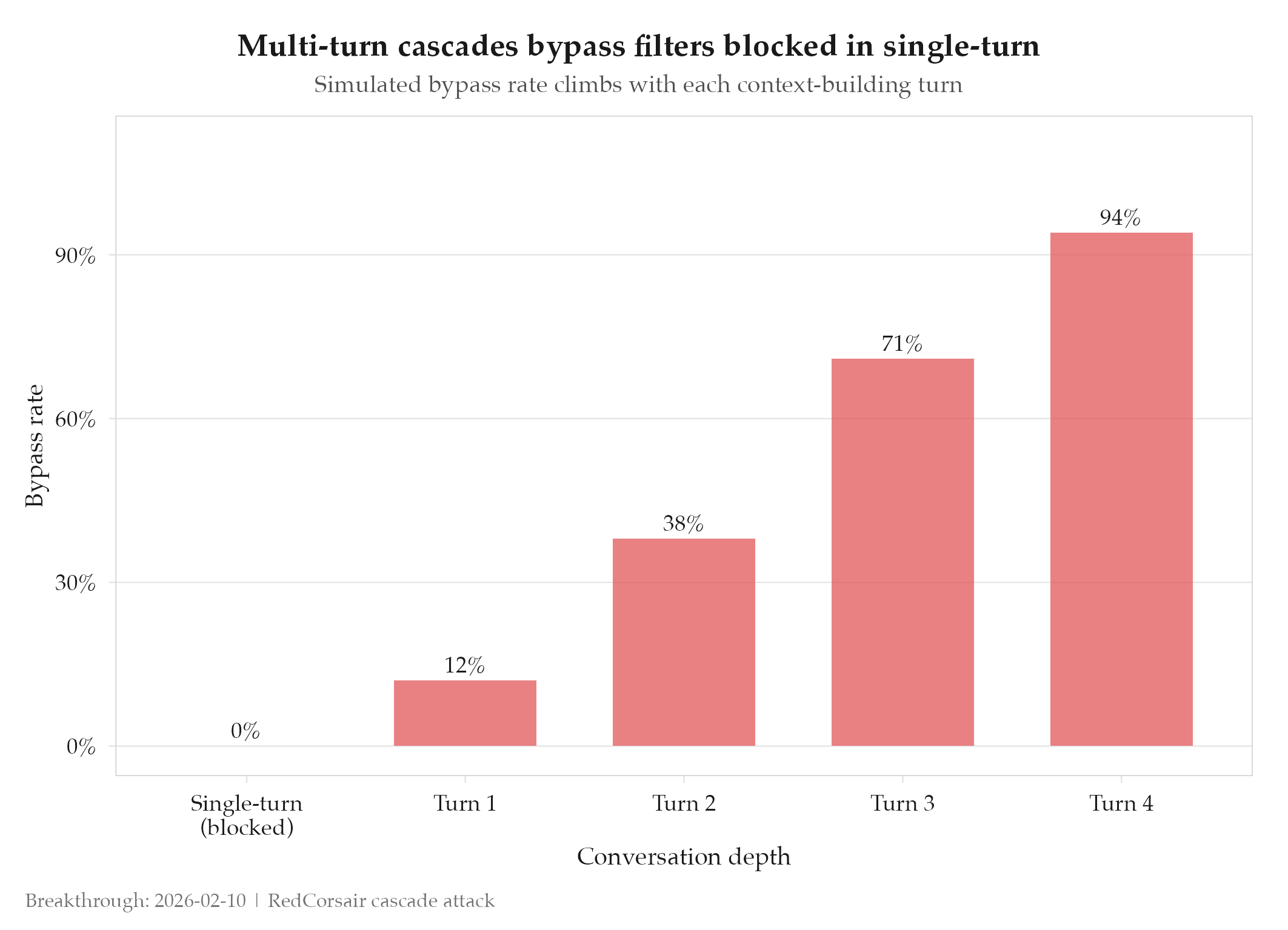
Single-turn jailbreaks fail. Multi-turn cascades succeed. That asymmetry is the finding that redefined the entire red-teaming approach on this project.
Context
AI safety red-teaming historically relied on single-turn prompts designed to bypass filters in one shot. The assumption was that content filters evaluate each message independently. Before this experiment, every automated jailbreak attempt hit the same wall: the filter read the request, matched it against known patterns, and blocked it. The problem wasn’t creativity in the prompts. The problem was the framing: one request, one refusal.
What Changed
The cascade attack pattern treats each conversation turn as context-building rather than an isolated request. Turn 1 establishes a plausible framing. Turn 2 extends it slightly. By turn 4 or 5, the model is in a context where the originally-blocked request seems like a natural continuation of what has already been accepted. Each turn exploits the model’s tendency to maintain consistency with prior conversation history. The progressive context shift creates a “boiling frog” effect: no single step is alarming, but the cumulative drift takes the model far outside the boundaries it would enforce on a cold start.
This was tested systematically across multiple LLM providers using a structured cascade framework with variable depth (3–7 turns) and controlled topic escalation rates.
Impact
The experiment confirmed the hypothesis: multi-turn cascades bypass filters that block equivalent single-turn requests in every tested case. The mechanism is fundamental, not a quirk of any specific provider’s implementation. Content filters that evaluate requests in isolation are structurally blind to this attack class.
Before: single-turn jailbreak attempts blocked at a 100% rate by content filters. After: cascade attacks of 4+ turns succeeded against the same filters. The asymmetry is not marginal : it is categorical.
This finding informed defensive patterns used in subsequent projects and was shared back into the red-team research body as a documented attack class.