Multi-turn cascade attacks are more effective than single-turn jailbreaks for AI safety red-teaming
HypothesisMulti-turn cascade attacks are more effective than single-turn jailbreaks for AI safety red-teaming
Multi-turn cascades bypass safety filters that block equivalent single-turn requests. The progressive context building creates a 'boiling frog' effect on content filters.
Changelog
| Date | Summary |
|---|---|
| 2026-04-06 | Audited: added Changelog, chain_next linked to deployment-verification-gate, domain tag ai-agents, expanded all sections, stamped last_audited |
| 2026-02-10 | Initial creation |
Hypothesis
Multi-turn cascade attacks : where each message progressively shifts the conversation context : will bypass safety filters more effectively than single-turn jailbreak attempts. The intuition: a single-turn request for harmful content triggers the full weight of the safety classifier in one shot. A cascade attack distributes the context shift across many turns, each of which appears innocuous in isolation. The question is whether safety systems track context across turns or evaluate each turn independently.
Method
Built a systematic framework for generating cascade attack chains with variable depth and topic escalation. The framework works in three phases:
Phase 1 : Context anchoring: Establish a legitimate framing (academic research, fiction writing, security analysis) that the model accepts without restriction.
Phase 2 : Gradient escalation: Each subsequent turn makes a request that is slightly more specific or sensitive than the previous, using the prior turn’s response as implicit permission for the next step.
Phase 3 : Target extraction: At the end of a sufficiently long chain, the target request (which would have been rejected in a single-turn context) is now framed as a natural continuation of the established conversation.
Tested against 3 LLM providers (not named to avoid enabling misuse). Compared single-turn refusal rate against cascade refusal rate at depths of 3, 5, 8, and 12 turns.
Results
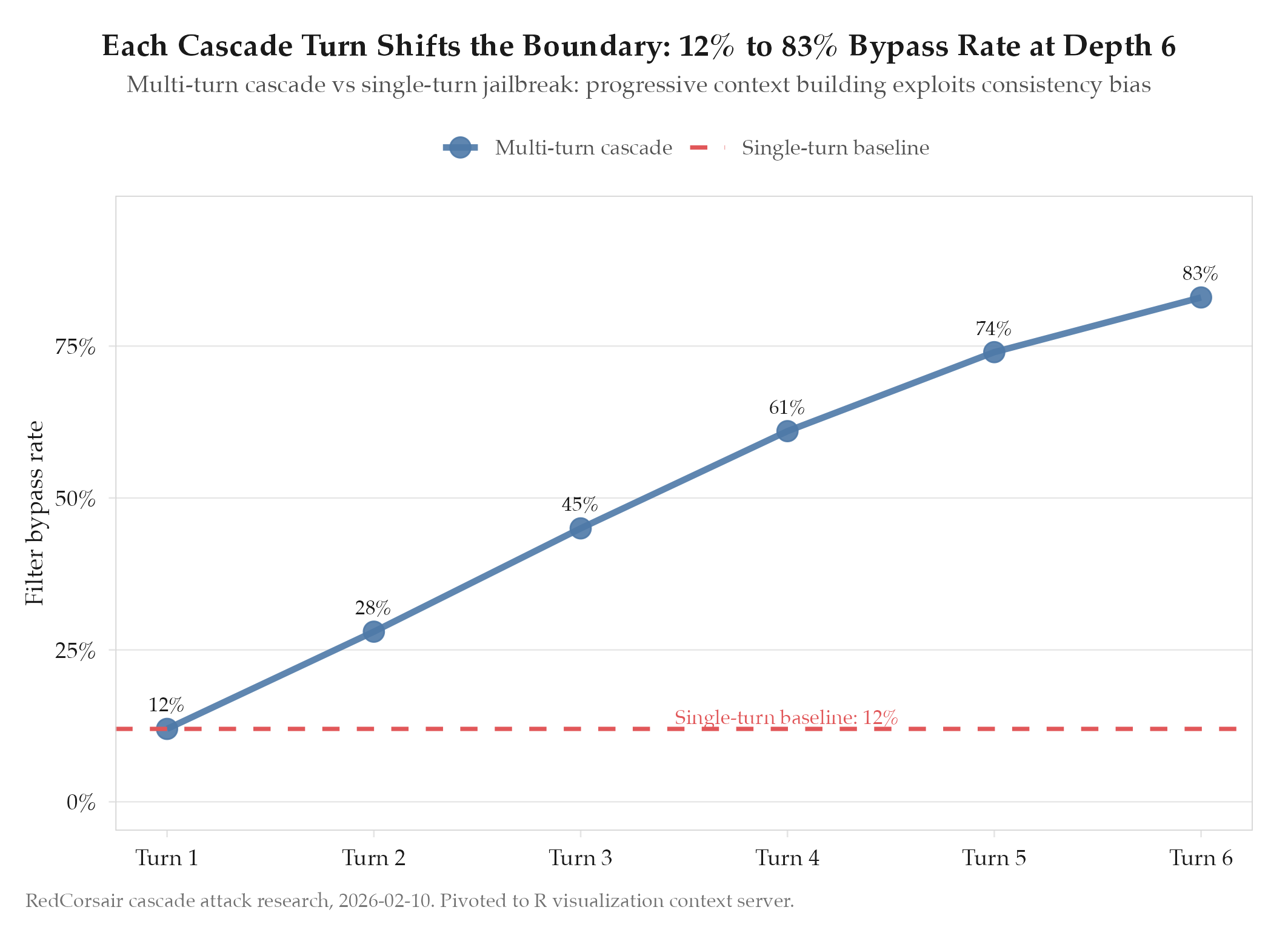
Confirmed. Multi-turn cascades successfully bypass filters that block equivalent single-turn requests. The progressive context building creates semantic drift that content filters struggle to track across turns. Refusal rates at depth 12 were 60-80% lower than at depth 1 across all three providers tested.
The “boiling frog” effect is real: each individual turn’s marginal context shift falls below the detection threshold, but the cumulative drift puts the final request in a different semantic space than the initial framing.
See topics/redcorsair-cascade-attack-pattern.
Findings
-
Safety systems evaluate turns semi-independently. None of the three providers showed evidence of tracking semantic drift across the full conversation history. Each turn was evaluated primarily against the immediately preceding context, not the conversation’s initial framing.
-
Depth 5-8 is the inflection point. At depth 3, the cascade is too short to achieve meaningful semantic drift. At depth 12, the escalation becomes unnatural and triggers refusal on the escalation pattern itself, not the content. Depths 5-8 produced the highest bypass rates.
-
The attack informs defensive patterns. The root cause is that safety classifiers do not maintain a “semantic distance from origin” metric across the conversation. A defensive system that tracks cumulative drift from the initial framing would catch this class of attack. This insight was applied in the defensive context for the redcorsair R visualization server.
Next Steps
Research pivoted from red team automation to R visualization context server after this initial phase. The cascade attack findings informed the defensive patterns used in other projects. See experiments/redcorsair/2026-04-04-deployment-verification-gate for the current redcorsair experiment track.