self-improving-agent-patterns
User wants to design a self-improving agent system, select an improvement pattern, or avoid known pitfalls in autonomous improvement loops
Changelog
260428: Added cross-repo sibling reference
- Added
## Cross-Repo Siblingsection linking to~/Documents/self-improving-toolkit/knowledge/taxonomy.md - Drift detection via
sync-manifest.jsonand vault pre-push hook
260427: Iteration-Objective taxonomy + Eval Harness dimension
- Added 8 Iteration Objectives (IO-1 through IO-8) as second taxonomy axis
- Added Huang Constraint as non-negotiable anti-pattern
- Added iteration_objective input to Interface
- Pattern count: 6 patterns x 8 objectives = 2-axis selection framework
- Added eval harness selection guidance (3 archetypes x 8 IOs compatibility)
- Added eval_harness_type input and recommended_eval_archetype + eval_anti_pattern_checklist outputs
260420: multiple edits
- v_migrate: Changelog migrated from table to YYMMDD H3 format per versioning-standard rule 2 (V1.6 of skills upgrade plan)
- v6: Added license, sources per V6.1/V6.2 of skills upgrade plan.
- v1.5: Added
## Quality Checkssection per V1.5 of ~/vault/plans/2026-04-20-vault-skills-upgrade-plan.md
260403: multiple edits
- Added patterns comparison chart (CMP, eval: 8.22)
- Added Visual Enrichment section + self-improving-agent-patterns cross-reference
260402: Initial creation: synthesized from 6 external self-improvement projects
Cross-Repo Sibling
Portable version: ~/Documents/self-improving-toolkit/knowledge/taxonomy.md (curated summary with decision tree + meta-hierarchy). This file is the rich operational reference. Conceptual changes to patterns, IOs, or eval archetypes need manual port to the sibling. Drift detection: vault pre-push hook reads sync-manifest.json.
Description
Use this when you need to design a system where an agent improves itself over time. It solves the pattern-selection problem: there are 6 distinct self-improvement architectures, each optimized for a different kind of improvement goal, and choosing the wrong one wastes months. This skill is a decision framework that maps your improvement goal to the right pattern, provides the architecture blueprint, and lists the anti-patterns that have caused production failures in the documented systems.
Synthesized from 6 external projects: AutoAgent (meta/task split, hill-climbing), Hermes Agent (persistent memory, skill crystallization, GEPA), Karpathy AutoResearch (autonomous experiment loop, metric ratcheting), Karpathy LLM KB (compiler wiki, lint+heal), Google TimesFM (zero-shot forecasting as predictive substrate), Microsoft Agent Lightning (RL training for any agent framework).
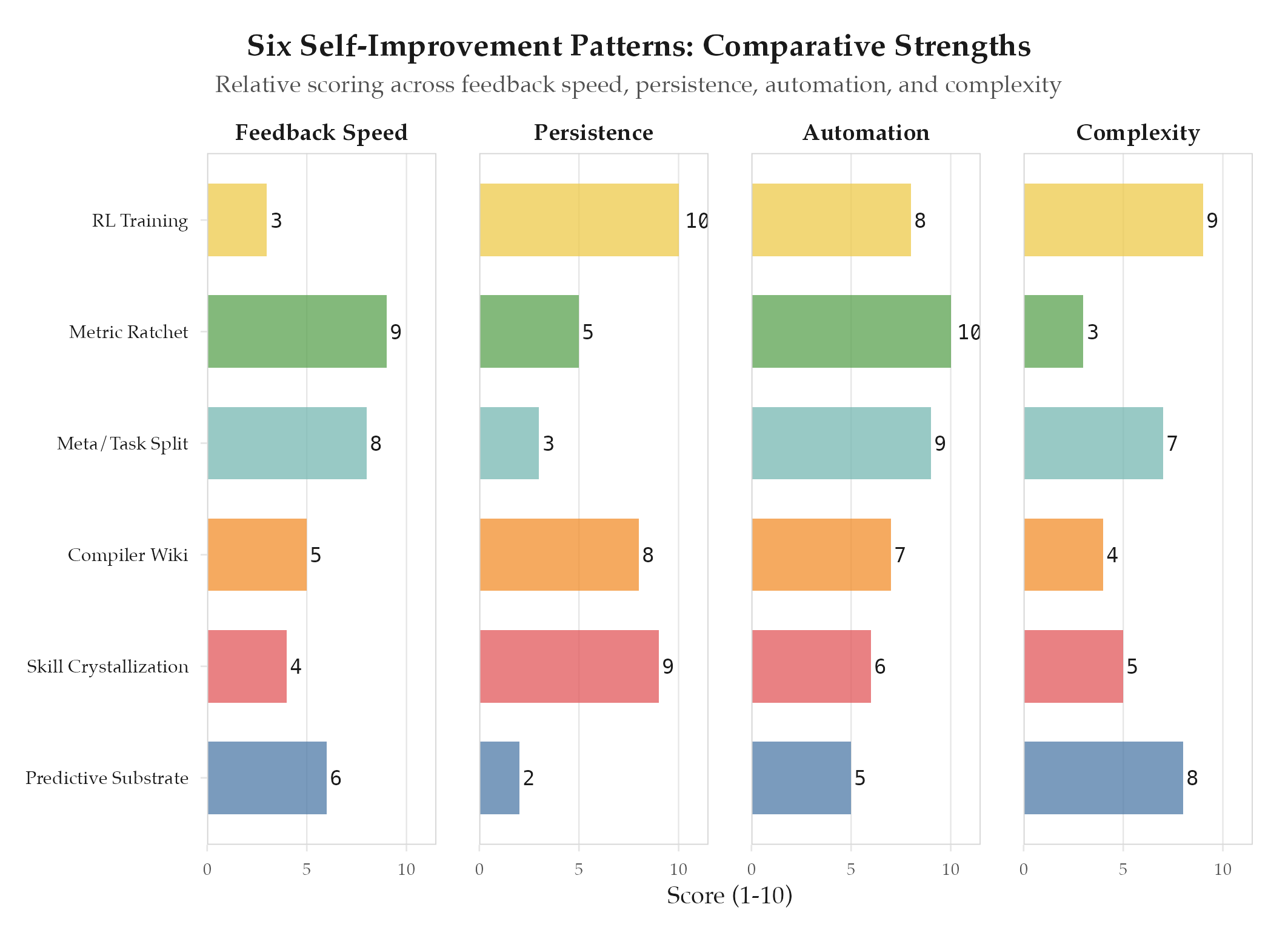 Six self-improvement patterns compared across feedback speed, persistence, automation, and complexity (composite eval: 8.22)
Six self-improvement patterns compared across feedback speed, persistence, automation, and complexity (composite eval: 8.22)
Interface
Trigger: Any of:
- “I want my agent to improve itself”
- “Which self-improvement pattern should I use?”
- “How do I avoid exploration collapse / metric gaming / memory bloat?”
- “Design a self-improving system for [domain]”
- “What are the best practices for autonomous agent improvement?”
Inputs:
improvement_goal: what artifact should improve (code, config, knowledge base, prompts, agent harness, predictions)feedback_signal: what drives improvement (benchmark score, task success rate, scalar metric, article quality, prediction accuracy, RL reward)persistence_requirement: does improvement need to survive across sessions? (ephemeral ratchet vs persistent skills/memory)framework_constraints: existing infrastructure (LangChain, AutoGen, Claude Code, CrewAI, custom)iteration_objective: how should the improvement loop work? (goal-seeking, metric-ratcheting, reflection, search, evolution, adversarial, state-reconciling, stress-hardening)eval_harness_type: what provides external feedback (model-capability harness, application-quality harness, falsification harness, none/custom)
Outputs:
recommended_pattern: primary pattern selection with rationalearchitecture_blueprint: components, data flow, invariants for the chosen patternanti_pattern_checklist: pattern-specific failure modes to guard againstcomposition_options: which secondary patterns complement the primary choicerecommended_eval_archetype: which eval harness archetype matches the chosen IO patterneval_anti_pattern_checklist: LLM-as-judge bias risks specific to the chosen combination
The Six Patterns
| # | Pattern | What Improves | Key Question | Key Invariant | Vault Instance |
|---|---|---|---|---|---|
| 1 | Meta/Task Split | Agent orchestration | Have a benchmark suite? | Benchmark immutable | : |
| 2 | Skill Crystallization | Reusable procedures | Tasks recur with variations? | Skills evolve via GEPA | This vault’s skill system |
| 3 | Metric Ratchet | Single mutable config | Metric scalar + fast? | Immutable evaluator | skills/karpathy-ratchet |
| 4 | Compiler Wiki | Knowledge base | Have raw sources? | LLM writes; human curates | This vault (audit = lint) |
| 5 | Predictive Substrate | Improvement decisions | Have metric history? | Always a complement | : |
| 6 | RL Training | Model weights/prompts | Clear reward signal? | Reward cannot be gamed | : |
Sources: research/2026-04-02-autoagent-meta-agent-optimization, research/2026-04-02-hermes-agent-persistent-memory-skill-evolution, research/2026-04-02-karpathy-autoresearch-autonomous-experiment-loop, research/2026-04-02-karpathy-llm-knowledge-base-pattern, research/2026-04-02-timesfm-zero-shot-forecasting, research/2026-04-02-agent-lightning-rl-training-for-agents.
Refinement: numeric + fast (<5 min) feedback means Ratchet or Meta/Task Split. Improvement must persist across sessions means Skill Crystallization, Compiler Wiki, or RL Training. Agent already in production means Agent Lightning (zero rewrites). Pattern 5 (TimesFM) is always a complement, never primary.
The Eight Iteration Objectives
The Six Patterns above answer “what improves.” The Iteration Objectives answer “how does the loop converge?”
| IO | Objective | Signal | When to Use | Vault Instance |
|---|---|---|---|---|
| 1 | Goal-Seeking | Binary | Discrete completion condition, building new things | Ralph Loop |
| 2 | Metric-Ratcheting | Scalar | Single numeric metric, regression unacceptable | Karpathy Ratchet |
| 3 | Reflection-Accumulating | Verbal | Learning from failures, requires external grounding | Lifecycle Chain |
| 4 | Search-Exploring | Node eval | Multiple candidate approaches, backtracking useful | Ratchet hypothesis phases |
| 5 | Population-Evolving | Fitness | Diverse strategies needed, open-ended improvement | Multi-persona audit |
| 6 | Adversarial-Competing | Win/loss | Competitive pressure available, arms race dynamics | Agent-MQI |
| 7 | State-Reconciling | State delta | Continuous desired-state maintenance, self-healing | Stella hooks, repair-sweep |
| 8 | Stress-Hardening | Survival | Can inject controlled stress, antifragility goal | Probe suite |
Huang Constraint (non-negotiable): IO-3 degrades without external feedback. Every IO requires an external signal source. See topics/pitfalls/self-correction-without-external-feedback.
Pattern + IO composition: Each of the Six Patterns can be combined with multiple IOs. Example: Metric Ratchet (P3) naturally uses IO-2, but can layer IO-4 (search-exploring) for hypothesis generation. Ralph Loop uses IO-1 but Lever Ralph Loop layers IO-2 (staged metric gates) on top.
Composition
Useful combinations: Ratchet + Predictive Substrate (plateau detection), Skill Crystallization + Meta/Task Split (meta-agent that builds reusable skills), RL Training + Ratchet (train behavior, tune config on top), Compiler Wiki + any pattern (every improvement auto-documented). Layer a secondary only after the primary is stable.
Eval Harness Selection
Every iteration objective needs external feedback (the Huang Constraint). Match the eval archetype to the IO:
| Iteration Objective | Primary Eval Archetype | Why |
|---|---|---|
| IO-1 Goal-Seeking | Model-Capability | Binary pass/fail is deterministic |
| IO-2 Metric-Ratcheting | Model-Capability | Scalar metrics need deterministic, reproducible scoring |
| IO-3 Reflection-Accumulating | Application-Quality | Rich, multi-axis feedback enables self-critique |
| IO-4 Search-Exploring | Any (depends on node eval) | Match to what you’re exploring |
| IO-5 Population-Evolving | Application-Quality | Fitness assessment needs quality judgment |
| IO-6 Adversarial-Competing | Falsification | Discrimination tasks match adversarial loops |
| IO-7 State-Reconciling | Model-Capability | State delta checks are deterministic |
| IO-8 Stress-Hardening | Falsification | Probe survival is binary discrimination |
Default heuristic: if your feedback signal is a number, use Model-Capability. If it requires judgment, use Application-Quality (with structured decomposition). If it tests defect detection, use Falsification.
Anti-pattern: using Application-Quality (LLM-judge) when Model-Capability (deterministic) is available. LLM-judge adds variance and bias; use it only when deterministic scoring is impossible. See topics/pitfalls/llm-as-judge-epistemic-biases.
Full benchmark catalog: topics/eval-harness-benchmark-catalog.
Anti-Pattern Checklist (10 required)
- Immutable evaluation: evaluator cannot be gamed by what it measures
- Monotonic gains: improvements locked, floor never drops
- Full observability: every experiment, keep, discard, metric logged
- Separation of concerns: what changes is distinct from what measures
- Exploration budget: mechanism to prevent policy collapse
- Staleness detection: improvement rate drop to noise floor is detected
- Human oversight: emergency stop and direction-change capability
- Bounded state growth: memory/skills/knowledge have compaction or eviction
- Cross-session persistence: improvement state survives session boundaries
- Model dependency documented: capabilities assumed, tested across models
Provenance
Synthesized from 6 external research notes (all dated 2026-04-02): research/2026-04-02-autoagent-meta-agent-optimization, research/2026-04-02-hermes-agent-persistent-memory-skill-evolution, research/2026-04-02-karpathy-autoresearch-autonomous-experiment-loop, research/2026-04-02-karpathy-llm-knowledge-base-pattern, research/2026-04-02-timesfm-zero-shot-forecasting, research/2026-04-02-agent-lightning-rl-training-for-agents.
Vault applications: skills/karpathy-ratchet (v2.0, Pattern 3, 9 experiments across 3 projects). Hub topic: topics/self-improving-agent-patterns.
Usage Notes
- Start with the pattern selection table. Most improvement goals map cleanly to one primary pattern.
- Layer a secondary only after the primary is working and stable.
- The anti-pattern checklist is non-negotiable before any deployment.
- Ratchet vs Meta/Task Split: single scalar metric means Ratchet; optimizing the orchestration layer means Meta/Task Split.
- Pattern 5 (TimesFM) is always a complement, never a primary.
- Pattern 4 (Compiler Wiki) is what this vault uses. The 14 audit skills are the lint+heal cycle.
- Log everything including discarded experiments. Negative results constrain future hypotheses.
- 80% of experiments will be discarded. That is normal, not a sign of failure.
Quality Checks
- Each of 6 patterns has ≥1 vault instance. Ratchet →
[skills/karpathy-ratchet](/skills/karpathy-ratchet), Compiler Wiki → this vault itself, etc. Missing instances = pattern isn’t load-bearing. - Anti-pattern checklist ≥10 items. Current: 10 items covering immutable evaluation, monotonic gains, observability, separation, exploration budget, staleness, oversight, bounded state, cross-session persistence, model dependency.
- All 6 pattern sources cite research notes. Each pattern references its
[research/2026-04-02-...](/research/2026-04-02-...)origin note. - 40/40 skills cross-reference this skill. Enforced by the
skills.self_improvement_xrefscanner; verify withrv audit --dimension skills. - Composition rules documented. Ratchet + Predictive Substrate, Skill Crystallization + Meta/Task Split, RL + Ratchet layering rules present in
## Composition. - Pattern selection flowchart exists. Figma diagram rendered; referenced from the Description.
- Each of 8 IOs has ≥1 vault instance. IO-1 Ralph Loop, IO-2 Karpathy Ratchet, IO-3 Lifecycle Chain, IO-4 Ratchet phases, IO-5 Multi-persona audit, IO-6 Agent-MQI, IO-7 Stella hooks, IO-8 Probe suite.
- Huang Constraint documented. Link to pitfall entry present. External-feedback requirement stated.
- Each of 3 eval archetypes has ≥1 vault instance. Model-Capability → Oil LOO, Application-Quality → Agent-MQI, Falsification → Probe suite.
- IO x Eval compatibility matrix documented. 8x3 matrix present in topic and skill files.
Visual Enrichment
When this skill produces output that benefits from visualization:
| Finding Type | Tool | Specification |
|---|---|---|
| Pattern comparison across projects | R viz (skills/r-visualization-pipeline) | Family: CMP, Template: Journal |
| Pattern selection logic | Figma MCP (generate_diagram) | Type: Decision tree |
See topics/visual-output-routing for the full routing decision framework.
Self-improvement context: This is the master reference for all 6 patterns.