Redcorsair Method Signature Drift
What Happened
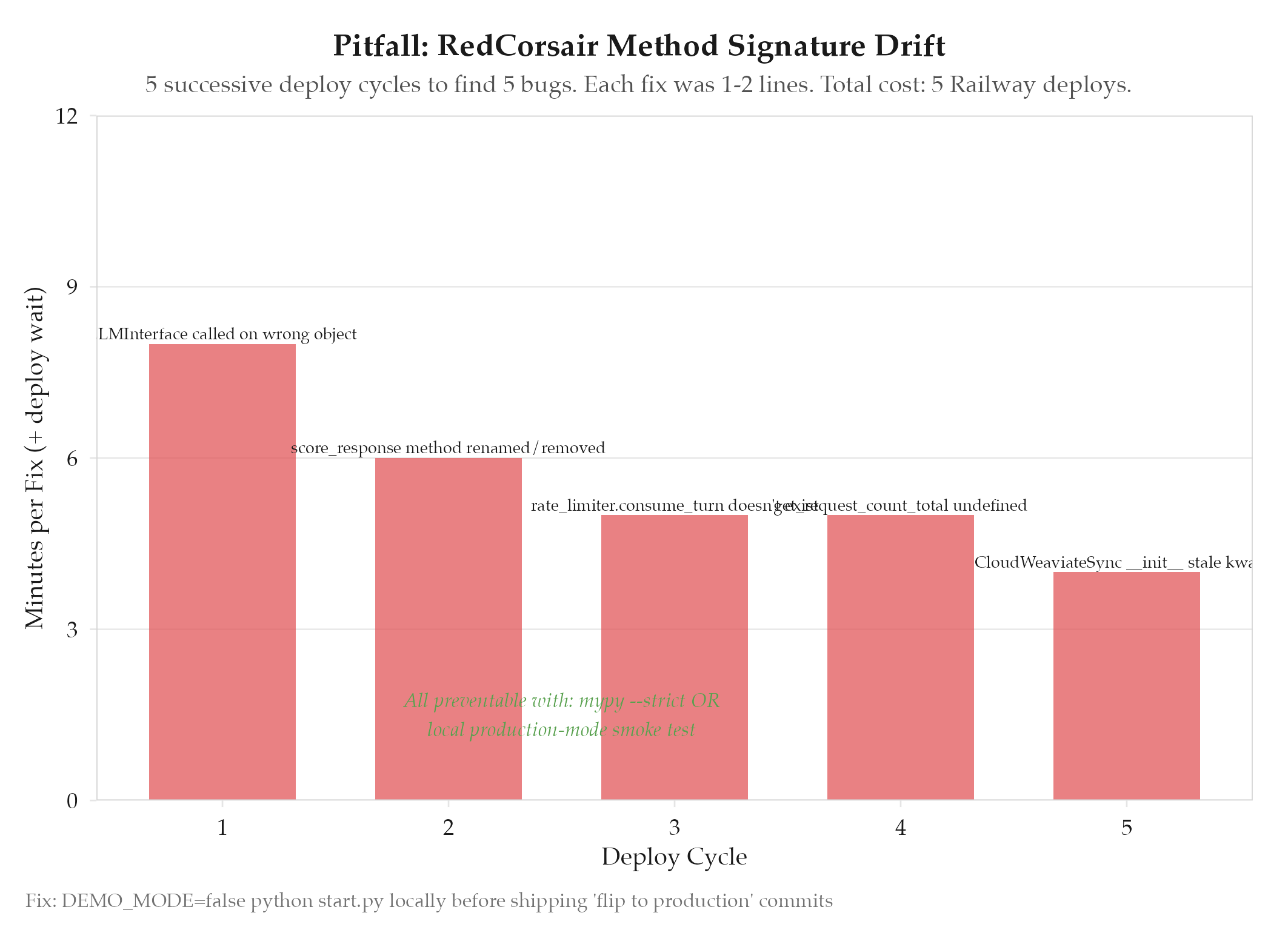
Enabling production mode (real LLM attacks instead of demo responses) triggered a chain of 5 rapid-fire failures in ~30 minutes. The MCP server called methods that no longer existed or passed arguments in the wrong order : all discovered at runtime in production, not locally.
Five failures surfaced in sequence, each requiring a Railway deploy cycle (minutes each) to discover:
LLMInterfacemethod called on wrong object : attack methods belong onTargetobjectsEnhancedJBAScorer.score_response: method renamed during an earlier refactor, caller still used old namerate_limiter.consume_turn: method planned but never implementedget_request_count_total: referenced in the health endpoint but never definedCloudWeaviateSync.__init__: constructor signature changed, caller using stale kwargs
Each fix was 1-2 lines. The cost was 5 separate deploy-and-fail cycles to Railway.
Root Cause
No static type checking and no integration test. Python’s dynamic dispatch means signature mismatches are invisible until runtime. Demo mode (DEMO_MODE=true) bypassed all the code paths that touched the broken methods, so every local test passed. The “flip to production” commit had never been run in production mode locally.
How to Avoid
- Run the server locally in production mode before deploying. A simple
DEMO_MODE=false python start.pywould have caught all 5 issues in seconds. - Use
mypy --strictorpyright. Method signature mismatches are exactly what static type checkers catch. - Integration smoke test. A single test that instantiates the MCP server and calls each endpoint (even with mock LLM responses) would surface all missing methods.
- Never ship a “flip to production” commit without local validation. The commit message said “Enable real MCP attack execution” : that flip should be tested before pushing.
Related
- projects/redcorsair/_index : parent project
- redcorsair-railway-deployment-saga
- redcorsair