Ollama Local Llm Abandoned
What Happened
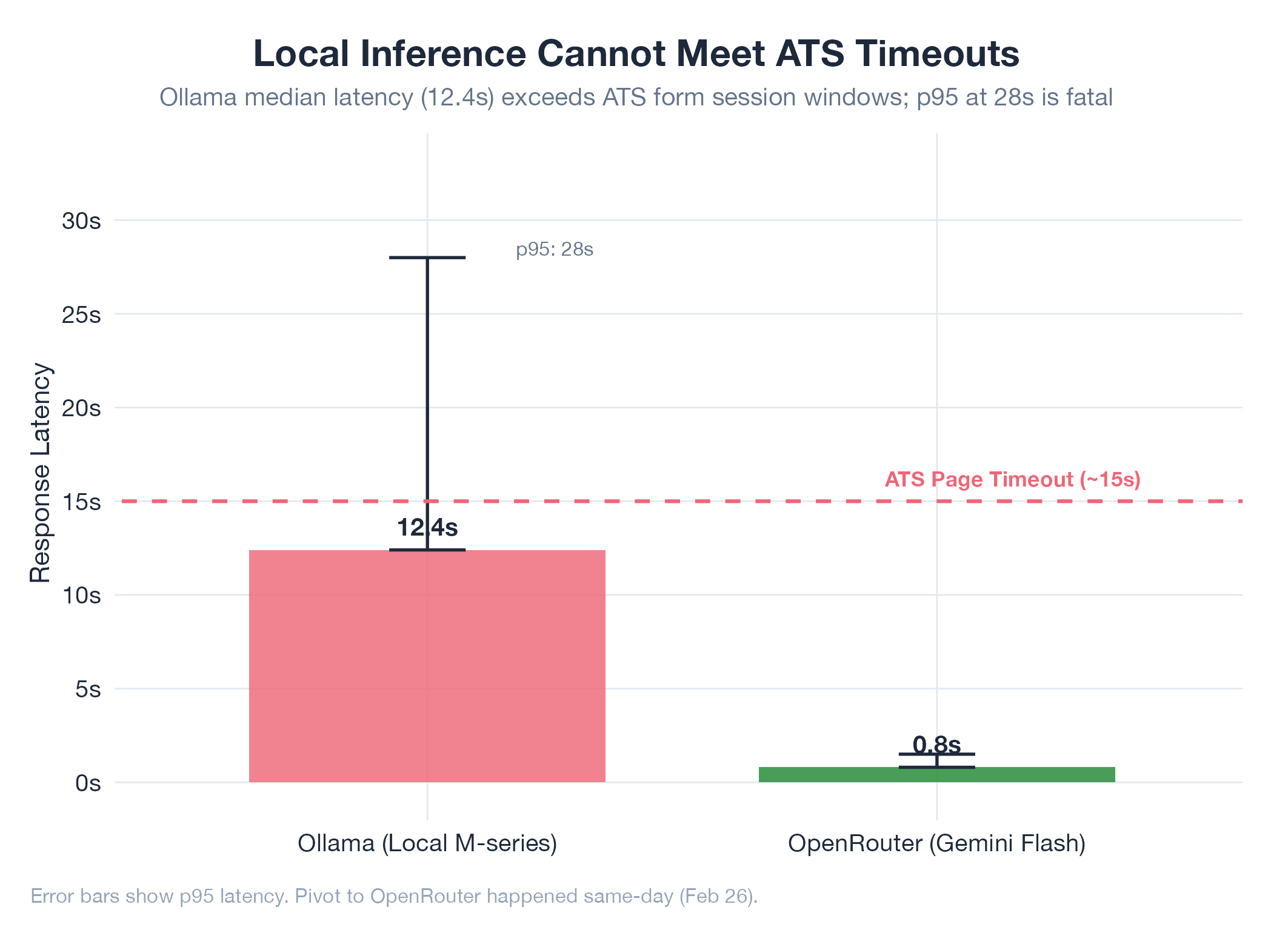
Initial AutoHunt architecture included Ollama (local LLM) as a primary AI provider alongside Claude. The plan was to run form-filling and job-matching inference locally to avoid API costs.
Root Cause
Local LLM inference was too slow for real-time form filling. ATS pages have submission timeouts: the form must be filled before the session expires. Ollama on consumer hardware (M-series Mac) could not complete multi-field form analysis within these windows. Response quality was also inconsistent for the structured extraction tasks required (parsing diverse ATS field layouts into typed form data).
Fix
Replaced Ollama with OpenRouter as a unified API gateway routing to Gemini Flash. OpenRouter provided: consistent sub-second latency, multi-provider failover, single API key for all models, and free-tier access to Gemini Flash. The pivot happened same-day (Feb 26): Ollama provider created and abandoned within hours.
Lesson
For latency-sensitive automation that interacts with third-party web UIs, cloud inference beats local inference. The cost savings from local inference don’t materialize when the upstream system (the ATS page) has its own timeouts that your local model can’t meet.