Llm Audit Speed
Changelog
| Date | Summary |
|---|---|
| 2026-04-19 | Initial creation from vault-engine-architecture idea; mitigated via tiered heuristic/Haiku/Sonnet scoring |
LLM audit speed
When a vault or codebase audit is scored entirely by LLM calls, each individual check costs 1-5 seconds plus a tokens bill, and a full dimension audit (30-150 items) stretches to 30-60 seconds of wall time. Worse, LLM scorers drift into false-positive territory on boundary cases, which forces re-audit runs that double or triple the real cost. The audit that was supposed to be a lint step becomes the slowest step in the knowledge pipeline.
Symptom
- A single dimension audit (topics, pitfalls, research) takes 30-60 seconds
- Re-running the audit after a small edit costs the same; there is no incremental path
- 10-25% of flagged issues turn out to be false positives on inspection
- Audit cost is the dominant budget line for the knowledge engine; developers stop running it
- Obvious structural failures (missing frontmatter field, broken wikilink) take the same time and cost as subtle semantic failures
Root Cause
Per-frame LLM evaluation is the wrong tool for structural and schema checks. The model is asked to grade things a regex would answer in microseconds: is the created field present, is the domain one of ten allowed strings, does the body have two sentences. The LLM’s probabilistic nature then generates a false-positive tail (misreads formatting, flags valid-but-unusual phrasing) that forces re-runs and manual triage.
The deeper cause: the audit was designed as a one-pass LLM judge rather than a tiered pipeline. Cheap deterministic checks (schema, links, word count, regex patterns) were never peeled off into a pre-filter layer. Every check, regardless of semantic complexity, pays the full LLM cost.
Detection
Measure audit wall time and cost per dimension. If any of these hold, the pitfall is active:
- Single-dimension audit exceeds 10 seconds of wall time
- Re-audit of unchanged content costs the same as first audit (no incremental path)
- False-positive rate above 10% on spot-checked flagged issues
- Token cost per audit run tracks linearly with item count (no tiered short-circuit)
- Developers avoid running the audit because it is too slow to iterate on
Remediation
Split the audit into a tiered pipeline. Run the cheapest stage first; only escalate to the next tier when the current stage cannot resolve the check:
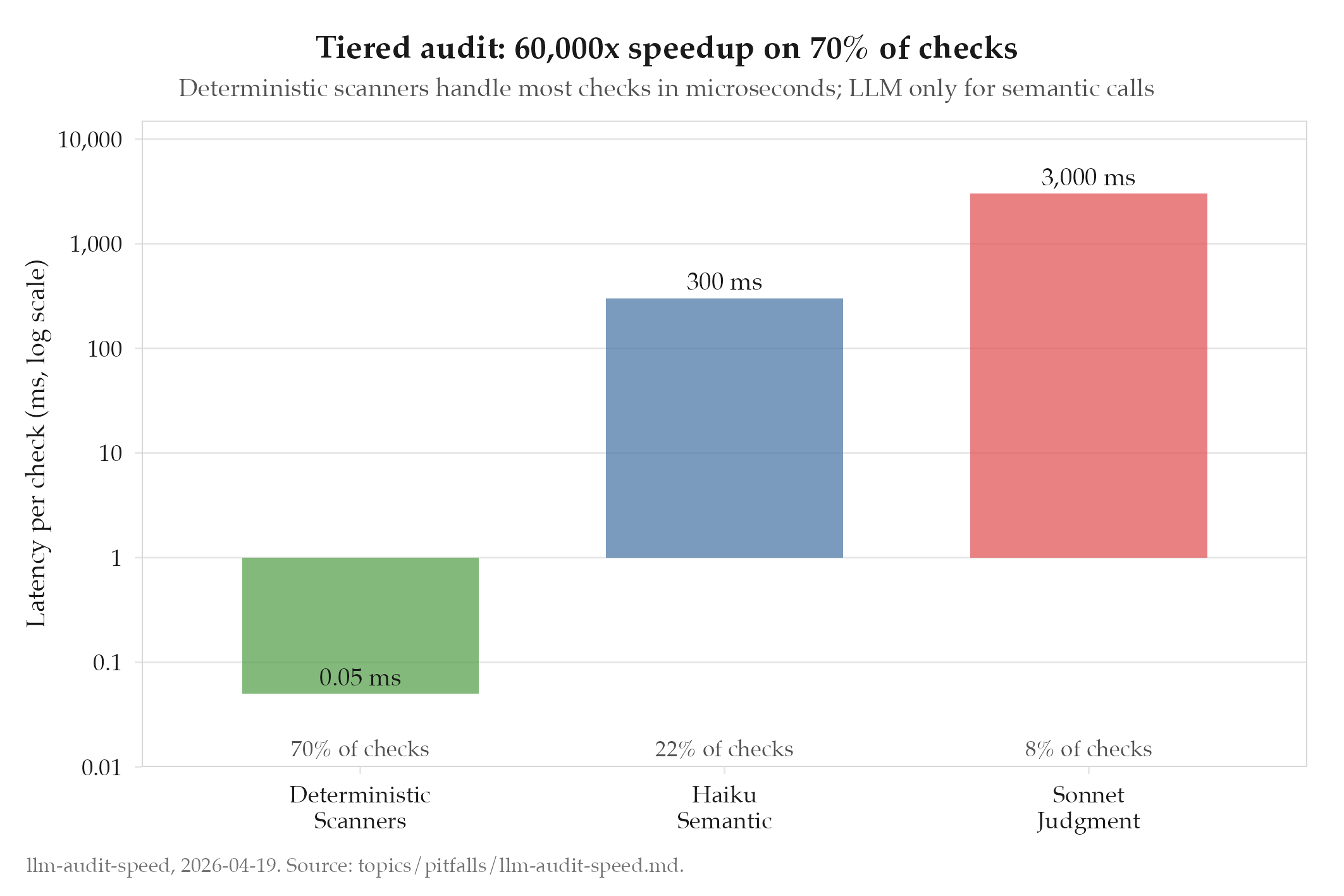
- Deterministic scanners (microseconds): schema validation, frontmatter field presence, wikilink integrity, word count, regex patterns, controlled-vocabulary membership. Written in Rust or Python. This handles ~70% of checks with zero LLM cost.
- Haiku tier (100-500ms): semantic sanity checks that need language understanding but not deep reasoning: is this sentence meaningful, does this tag match the body content, is this voice compliant. Cheap model, tight prompt, cached where possible.
- Sonnet tier (1-5s): hard semantic calls: is this claim supported by the cited research, does this body actually cover the topic, is the cross-link appropriate. Only invoked for items that passed tiers 1-2 but still need judgment.
Pair the tiering with content-hash invalidation: keep an audit_state table keyed by content hash, so unchanged items short-circuit the entire pipeline. This turns audit cost from linear in item count to linear in changed-item count.
The vault-engine-architecture idea from 2026-04-08 drove this exact restructure: see ideas/2026-04-08-vault-engine-architecture and the resulting breakthrough note.
Related
- ideas/2026-04-08-vault-engine-architecture: the idea that originally surfaced this pitfall
- topics/pitfalls/circular-knowledge-corruption: sibling pitfall in the KNOWLEDGE cluster
- topics/pitfalls/agent-memory-bloat: another audit-cost pattern: unbounded state growth
- skills/audit-topics: deterministic scanner implementation for the topics dimension
- skills/audit-pitfalls: deterministic scanner implementation for the pitfalls dimension
- skills/karpathy-ratchet: iterative-optimization pattern underlies the tiered design
- projects/stella/_index: parent project for the vault knowledge engine work