Hourly cron beats streaming when missed updates are cheap and failed updates are expensive
2026-03-15
Signal
Choosing hourly cron over streaming for the oil model’s auto-refresh revealed a design principle that transfers broadly: reliability matters more than latency for systems where the cost of a missed update is low and the cost of a failed update is high.
Evidence
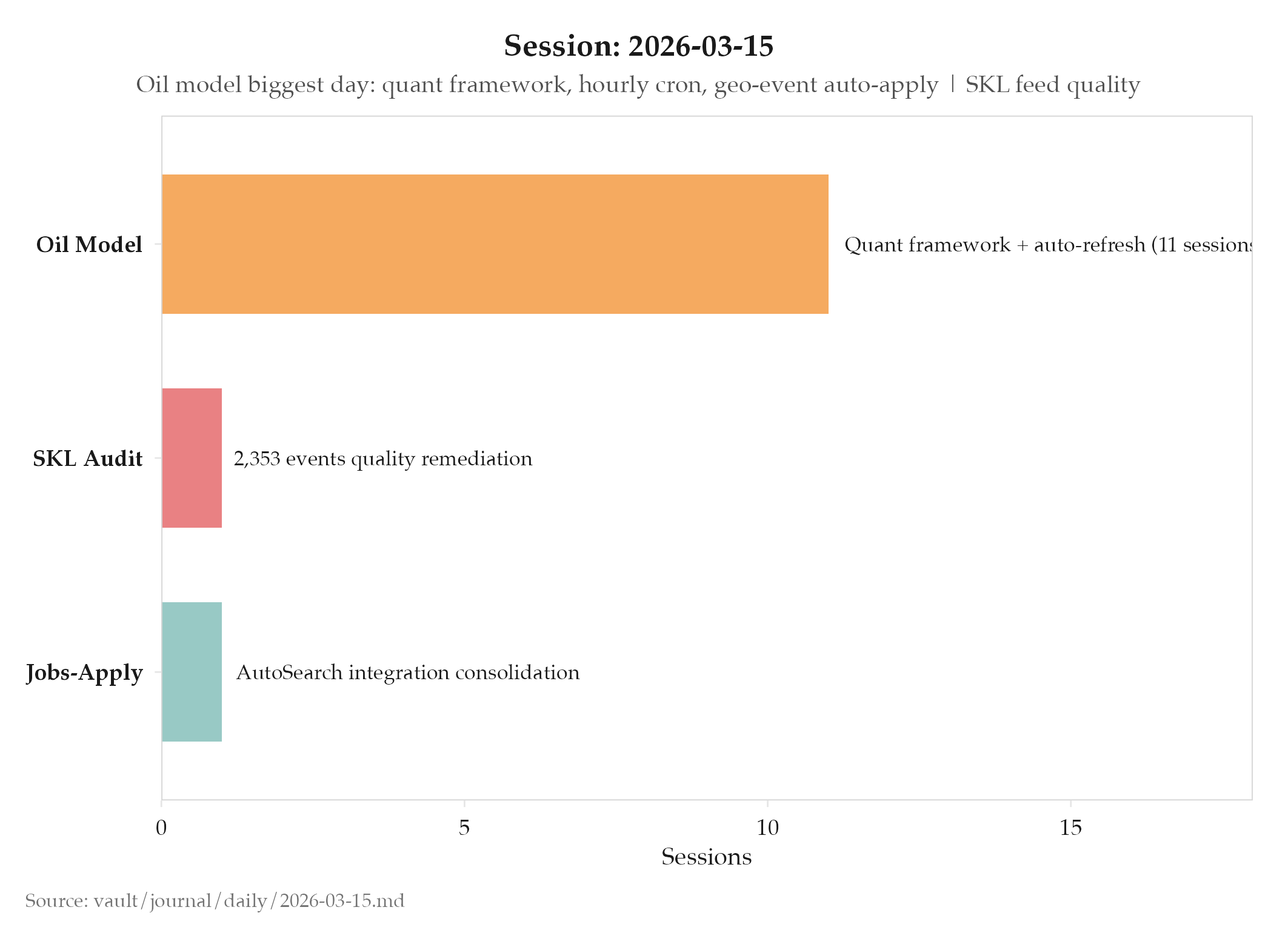
- Project: projects/oil/_index: 11 sessions: Quant Framework Plan, Dashboard Hourly Auto-Refresh, Geopolitical Auto-Apply System
- Decision: Hourly cron chosen over streaming for model refresh: reliability > latency for this use case
- Architecture: Externalized data pipeline + hourly cron for automated model updates; automatic application of geopolitical events to model parameters
- Project: internal audit: Data Quality Remediation Plan targeting 2,353 events across 534 places; pipeline-integrated feed quality system to catch null-date events and misclassified articles
- Decision: Feed remediation as pipeline stage, not post-hoc script: fixes problems at ingestion, not after scoring
- Project: projects/jobs-apply/_index: AutoSearch integration plan merged into Claude file
So What (Why Should You Care)
The cron vs. streaming decision for the projects/oil/_index model applies to any system that processes real-time data feeds but doesn’t require real-time output. Oil futures prices update continuously, but the model’s downstream consumers: people making positioning decisions: operate on minute-to-hour timescales. Streaming the data would add significant operational complexity: persistent connection management, reconnection logic after failures, backpressure handling when the downstream model can’t keep up. All of that complexity would be spent to deliver updates that arrive faster than they can be acted upon.
The hourly cron is reliable, auditable, and operationally simple. If a cron run fails, you know exactly when it failed and why. If a streaming connection drops, you may not notice until you look at the data and realize it’s been stale for three hours. For systems where the cost of a missed update is low and the cost of an undetected failure is high, cron wins over streaming every time.
The same reliability vs. complexity tradeoff appears in the internal audit feed remediation decision. Running quality checks at ingestion time (pipeline stage) rather than after scoring (post-hoc script) changes where bad data becomes visible. A pipeline-stage check blocks null-date events from entering the system at all: they’re rejected at the door. A post-hoc script finds them after they’ve already been processed, scored, and potentially included in reports. The cost of a bad record scales with how far it travels through the pipeline before being caught.
This is the “fail early” principle applied to data pipelines. Every downstream step that processes a bad record represents wasted computation and potentially contaminated downstream artifacts. Catching the record at ingestion eliminates that waste entirely. For the 2,353 null-date events across 534 places identified today, the pipeline-stage check prevents all of those records from ever reaching the scoring layer: reducing both computational cost and the risk of a bad record affecting quality scores.
The Geopolitical Auto-Apply System for the oil model is worth noting for a different reason: it closes a manual step that was creating inconsistency. When GL-134 was added manually on 2026-03-12, it required remembering to update the model. An auto-apply system that reads geopolitical events and updates model parameters automatically eliminates that manual dependency.
What’s Next
- Validate geopolitical auto-apply system with real events
- Monitor null-date event detection in the pipeline-integrated feed quality system
Log
- projects/oil/_index: 11 sessions: largest oil model day so far
- Quant Framework Plan: full implementation for CL Futures Hormuz Model
- Dashboard Hourly Auto-Refresh: externalized data pipeline, hourly cron for automated model updates
- Geopolitical Auto-Apply System: automatic application of geopolitical events to model parameters
- Multiple ultrathink planning sessions with quant persona
- Key decision: hourly cron over streaming: reliability > latency for this use case
- internal audit: Data Quality Remediation Plan for 2,353 events across 534 places
- Pipeline-integrated feed quality system to catch null-date events and misclassified articles
- Key decision: feed remediation as pipeline stage, not post-hoc script
- projects/jobs-apply/_index: merged AutoSearch integration plan into Claude file