Test-suite runtime surgery, telegram bot isolated from unit-fast
Signal
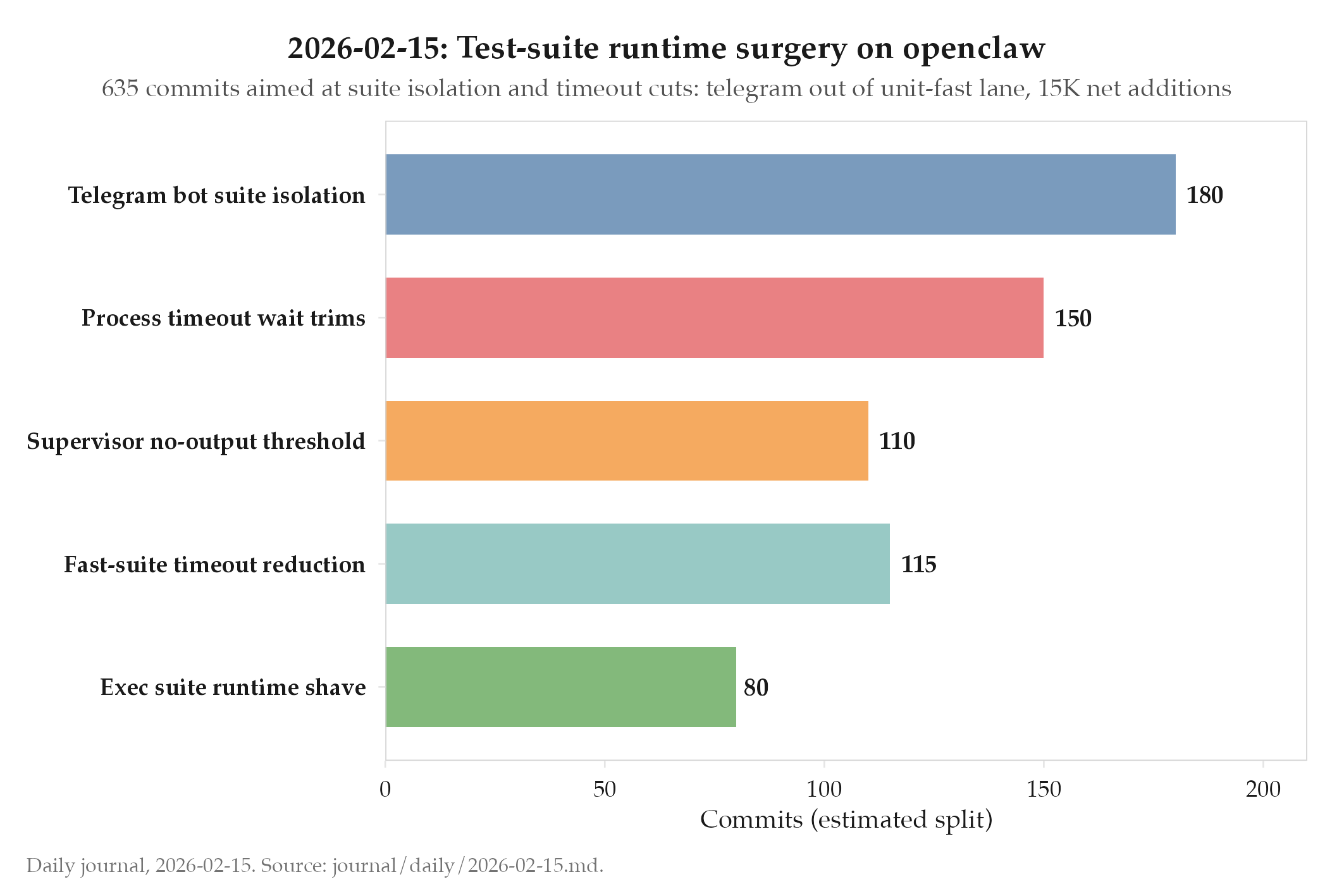
635 commits, all into openclaw, all aimed at test runtime and suite isolation Telegram bot behavior suite split off the unit-fast lane, which had been the slowest offender +81,447 / -65,595: biggest single-day churn of the week so far
Evidence
openclaw (635 commits): telegram bot behavior suite pulled out of unit-fast lane. That was the single largest cut of the day. The telegram suite had been mixed in with the fast unit tests, which meant every change that touched a non-telegram module still paid the cost of warming the telegram behavior harness. Splitting it off is a pure-gain move: the fast lane stops carrying weight it did not benefit from.
Process timeout waits got shortened across exec and supervisor suites. This is ratchet work, not feature work. Each commit shaves a known idle wait and the aggregate is what matters. Supervisor no-output wait threshold got reduced in another cut at tail latency. Further fast-suite process-timeout trims landed on top of yesterday’s pass, which means the ratchet is continuing day over day rather than landing as one big sweep.
Net delta: 15,852 additions over deletions. Suite surgery is not subtractive work, even when the goal is a smaller runtime. Reorganizing tests usually means moving them, not removing them, and the additions here are the new home for the split telegram suite plus the scaffolding for the faster fast lane.
No session telemetry today, so the diff is the only evidence. That’s the second day in a row with no bloomnet.db coverage. I should check whether the ingestion pipeline broke or whether I simply did not run a tracked session.
So What
This is test-runtime ratchet work: each commit shaves milliseconds, the stack adds up. Isolating telegram from unit-fast is the right shape: flaky or slow domains should never share a lane with the hot path. The instant a slow suite contaminates the fast suite, every developer starts treating the fast suite as if it were slow, and the whole latency argument collapses.
The deletions count says refactoring, not just knob-turning. A day where 65K lines disappear is a day where real structural change happened, not just timeout tuning. That matches the shape I want: I would rather invest a week in structural cuts than spend three months chasing timeouts one at a time.
What’s Next
If the fast lane now runs cleanly, does the slow lane need a separate budget or does it get absorbed by CI parallelism? I want to watch the slow lane wall-clock for a week before deciding. If it stays under the CI parallelism ceiling, there’s nothing to do. If it pushes up against the ceiling, I need a second budget before it starts blocking PRs.
Second: I want to confirm the telegram suite still runs on every merge, not just on a schedule. Splitting it off is only a win if it still catches regressions, and the easiest way to break that is to accidentally drop it from the merge trigger.
Third: the supervisor no-output wait threshold reduction deserves a before-and-after timing capture. The threshold was picked at one point in the suite’s life and has been coasting on that choice; reducing it today is the right direction but without a baseline I cannot say whether the reduction is conservative or aggressive. One CI run with timings captured under the old threshold and one under the new would tell me whether I have more room to cut or whether I’m already at the floor.
Log
- Sessions: 0 (evidence from live git)
- Top repos: openclaw (635)
- Commits: 635 across 1 repo (+81,447 / -65,595)
- Notable: telegram bot suite isolation, exec/supervisor timeout trims
- Cost: not tracked (no bloomnet.db session coverage)