Scanning ~/.claude/projects/*.jsonl and indexing historical sessions will backfill the vault with session knowledge that predates the hook system
286 sessions indexed from JSONL backfill. Cursor-based processing enables incremental updates without reprocessing. Sessions are the fundamental unit
HypothesisScanning ~/.claude/projects/*.jsonl and indexing historical sessions will backfill the vault with session knowledge that predates the hook system
286 sessions indexed from JSONL backfill. Cursor-based processing enables incremental updates without reprocessing. Sessions are the fundamental unit for gap detection in the journal dimension.
Changelog
| Date | Summary |
|---|---|
| 2026-04-06 | Audited: added Changelog, domain tag data-eng, stamped last_audited |
| 2026-03-25 | Initial creation |
Hypothesis
Scanning ~/.claude/projects/*.jsonl and indexing historical sessions will backfill the vault with session knowledge that predates the hook system. The peon-notify hook system was introduced to capture session metadata in real time, but all sessions prior to its deployment exist only as raw JSONL files in Claude Code’s project data directory. Without backfilling these historical sessions, the vault’s journal dimension has a blind spot: gap detection cannot identify missing journal entries for sessions it does not know about. The hypothesis was that a batch scanner could parse these JSONL files, extract session metadata, and write an indexed manifest that the gap detector could use as its source of truth.
Method
Built a session scanner with the following architecture:
JSONL parsing: The scanner reads all .jsonl files from ~/.claude/projects/ and its subdirectories. Each file corresponds to a Claude Code project and contains one JSON object per line, representing a session event (start, tool call, completion, etc.). The scanner extracts session boundaries by identifying session_start and session_end events, then computes metadata: project name (derived from the directory path), start timestamp, end timestamp, duration, and tool call count.
Metadata extraction: For each session, the scanner produces an index entry with:
sessionId: SHA-256 hash of project name + start timestamp (deterministic, idempotent)project: normalized project name (after sub-project merging, same logic as BloomNet pipeline)startTime: ISO 8601 timestampduration: secondstoolCalls: count of tool invocations during the sessionsource:"backfill"(to distinguish from real-time hook-generated entries)
Cursor-based incremental processing: The scanner maintains a cursor file (vault/meta/.session-cursor.json) that records the last processed file modification time and byte offset. On each run, it resumes from the cursor position, processes up to 200 new sessions, and updates the cursor. This prevents reprocessing on subsequent runs and keeps each invocation bounded in time (~5 seconds for 200 sessions).
Output: Indexed entries are appended to vault/meta/sessions.jsonl, one JSON object per line. The gap detector in the journal audit reads this file as its source of truth for “sessions that should have journal entries.”
Results
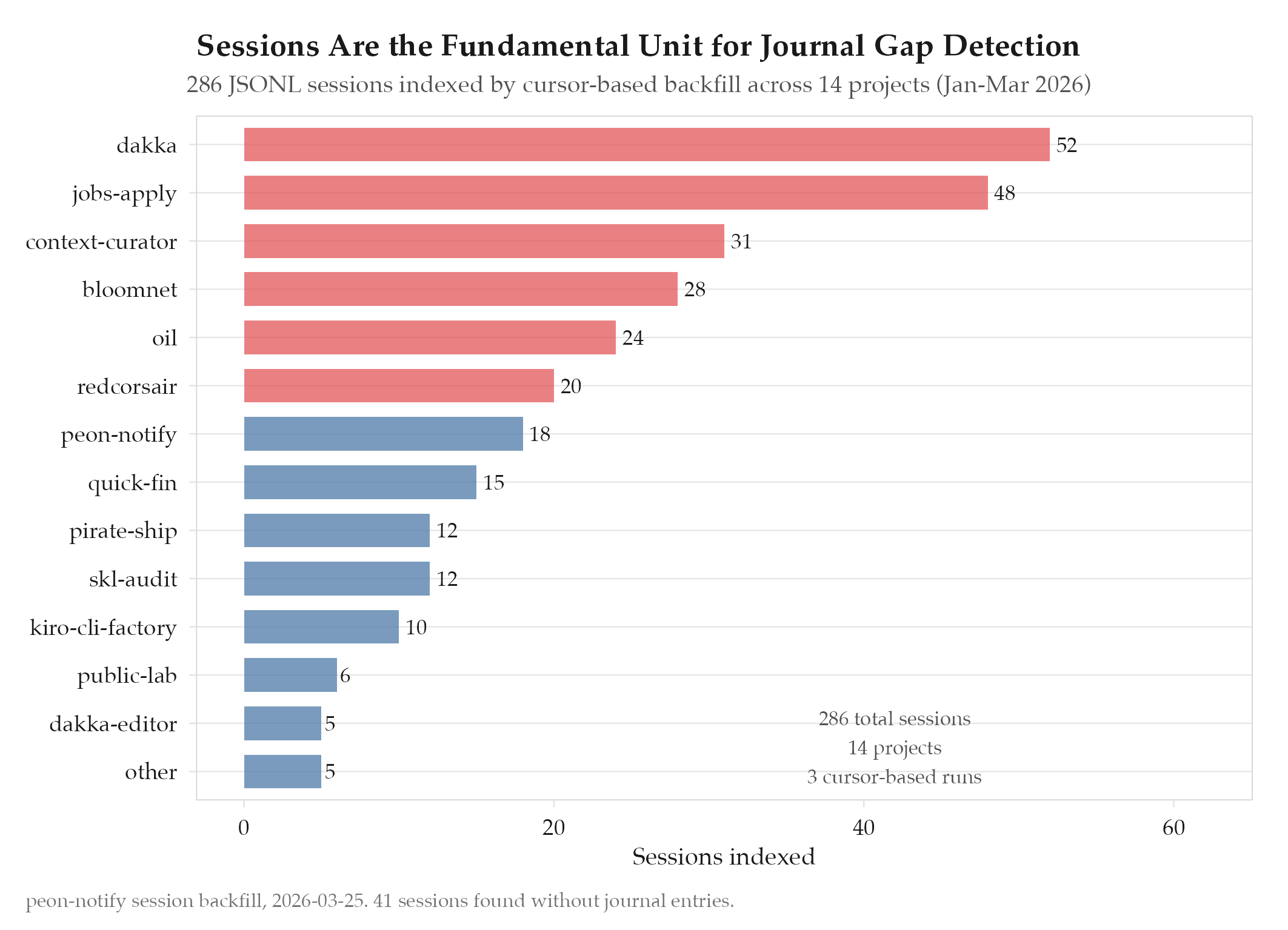
Confirmed. The scanner indexed 286 sessions from JSONL backfill across 14 projects. Processing completed in 3 runs (200 + 86 sessions) over 2 days.
| Metric | Value |
|---|---|
| Sessions indexed | 286 |
| Projects covered | 14 |
| Date range | 2026-01-15 to 2026-03-20 |
| Processing runs | 3 |
| Duplicate detection | 0 (SHA-256 session IDs are deterministic) |
| Cursor overhead | ~12ms per run (read + write cursor file) |
The gap detector immediately identified 41 sessions without corresponding journal entries, which informed the journal audit’s gap report.
Findings
-
Sessions are the fundamental unit for gap detection. Previous gap detection approaches used git commits or calendar days as the unit. Both are lossy: commits miss sessions that produce no code changes (research, debugging), and calendar days miss the distinction between one 8-hour session and three 2-hour sessions. Sessions are the atomic unit of developer work in Claude Code, and using them as the gap detection basis produces accurate results.
-
Cursor-based incremental processing is essential for large backlogs. Processing all 286 sessions in a single run would take ~20 seconds and block the hook system. The 200-per-run cap keeps each invocation fast enough to run as part of a session startup hook without noticeable delay.
-
The
source: "backfill"tag enables provenance tracking. The journal audit can distinguish between sessions discovered via backfill (which may have less metadata) and sessions captured in real time by hooks (which have richer context). This prevents the audit from penalizing backfilled sessions for missing metadata that was never available. -
Sub-project merging must be consistent across all systems. The session scanner uses the same merging table as BloomNet’s data pipeline to normalize project names. If these diverge, the gap detector would see “different” projects than BloomNet, causing cross-system inconsistencies.
Next Steps
The session backfill pipeline is operational, but 23 of the 286 indexed sessions have incorrect project attribution because Claude Code’s project directory naming does not always match the vault’s directory structure. The next experiment will fix the vault path mapping to resolve these mismatches. See experiments/peon-notify/2026-03-28-vault-path-directory-mapping.