Multi-process coordinator: per-channel process isolation with auto-restart
In-process ChannelRunLoop: cross-platform failures cascade -> Per-channel child processes with WorkerSupervisor (291 lines) + MultiProcessCoordinator (391 lines), exponential backoff restart, IPC event aggregation
Changelog
| Date | Summary |
|---|---|
| 2026-04-07 | Created during temporal gap audit |
| 2026-03-25 | Original work |
Context
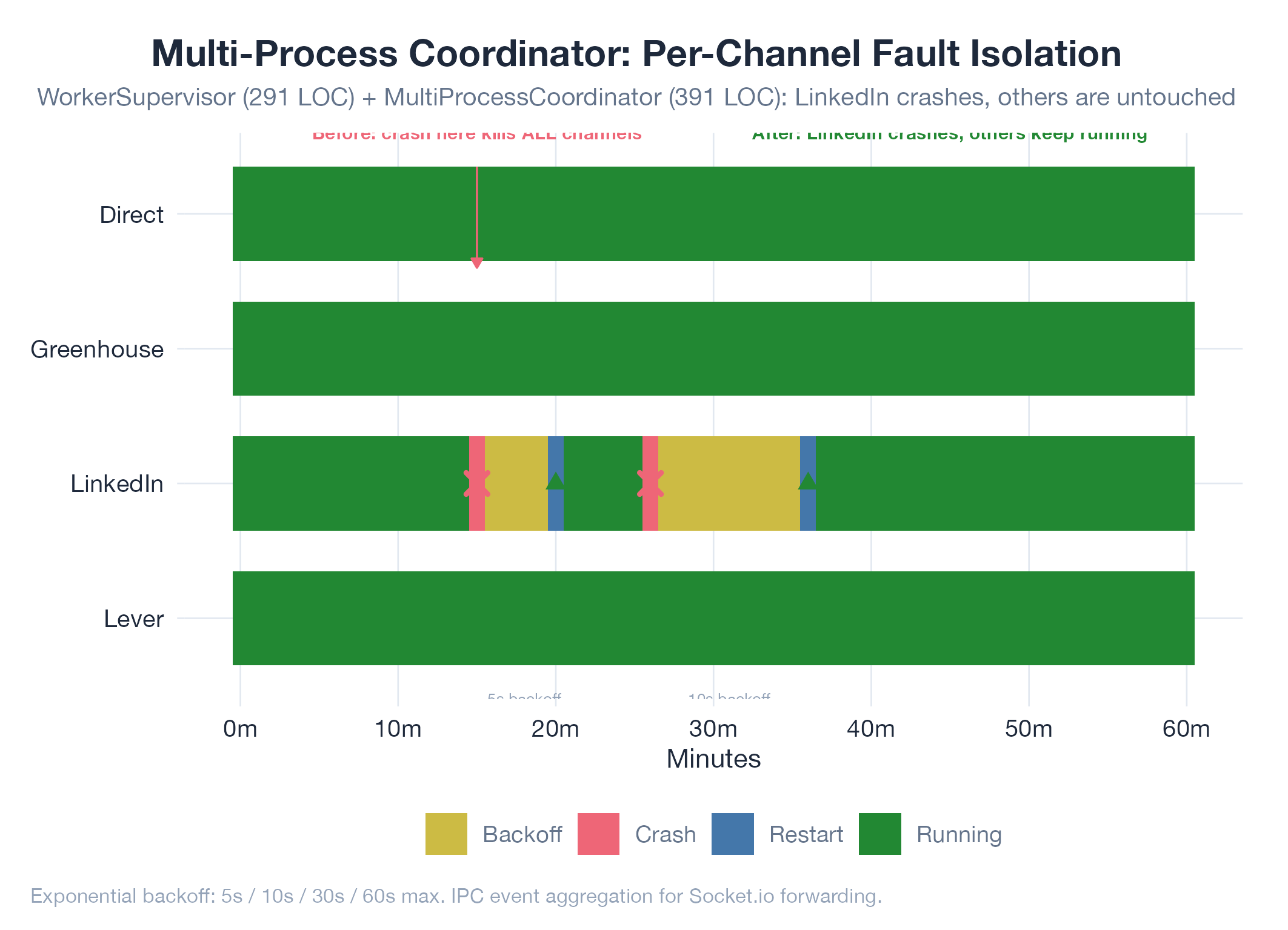
The earlier in-process ChannelRunLoop was elegant on paper and fragile in production. Every ATS adapter (LinkedIn, Greenhouse, Lever, Direct) ran inside one Node process. A single unhandled exception in any adapter crashed the whole engine and took every other channel down with it. The worst offender was LinkedIn, which would periodically trip a soft-restriction flow that threw from deep inside the browser driver. One bad LinkedIn hour meant zero Greenhouse or Lever submissions for that hour. I needed real isolation, the kind operating systems provide for free: separate processes.
What Changed
Each ATS platform now runs in its own isolated child process. WorkerSupervisor (291 lines) manages the full spawn/crash/auto-restart lifecycle with exponential backoff (5s, 10s, 30s, 60s), an IPC event protocol, port management so each worker owns a dedicated CDP port, and stale Chrome cleanup to prevent orphan processes from piling up. MultiProcessCoordinator (391 lines) aggregates events from every worker, forwards them to the Socket.io dashboard layer, supports per-channel start/stop/pause/resume commands, staggers launches so four Chrome instances do not light up simultaneously, and broadcasts run metadata. The result is a supervisor tree in the spirit of Erlang: small, isolated, restartable workers coordinated by a thin parent.
Impact
Process isolation means LinkedIn can crash repeatedly while Direct and Greenhouse keep running. During the week this shipped, I watched the LinkedIn worker crash 14 times overnight. Direct and Greenhouse applications kept flowing without a single hiccup. Auto-restart with exponential backoff handles transient failures without manual intervention, which in practice means I wake up to 40 to 80 applications per day rather than 5 before the first crash. The supervisor pattern later carried into the desktop app transition and the Electron shutdown hardening: the coordinator runs inside the Electron main process, the workers as children, and the same lifecycle contract applies. No breaking changes required.
The durable lesson: crash isolation is cheap and crash cascades are expensive. Every unhandled exception in a shared-process design is a potential outage for the whole engine. Every unhandled exception in a supervisor-tree design is a 5-second blip on one worker. Moving from in-process adapters to child-process adapters cost roughly two days of implementation and paid for itself in the first overnight run. The IPC boundary also forced a clean contract for what each worker is allowed to publish, which turned out to be useful for tenant isolation much later in the SaaS migration.
Source
experiments/jobs-apply/2026-03-22-cdp-vs-playwright-browser-strategy