Infinite run coordinator: persistent autonomous job application engine
Single-run tool requiring manual restart for each batch -> Persistent engine: per-channel state machines, quiet hours, stagger delay, daily limits, auto-pause on CAPTCHA, exponential backoff
Changelog
| Date | Summary |
|---|---|
| 2026-04-07 | Created during temporal gap audit |
| 2026-03-09 | Original work |
Context
Before this commit, jobs-apply was a glorified cron job. Start the script, watch a handful of applications land, then restart it when anything went sideways. Every CAPTCHA, every rate limit, every expired cookie meant a human sitting in front of a terminal. That model could not survive past the first long weekend. The goal all along was a machine that kept working while I slept, applied to the right roles across multiple platforms at once, and recovered from the routine failures a web-automation stack sees every hour.
What Changed
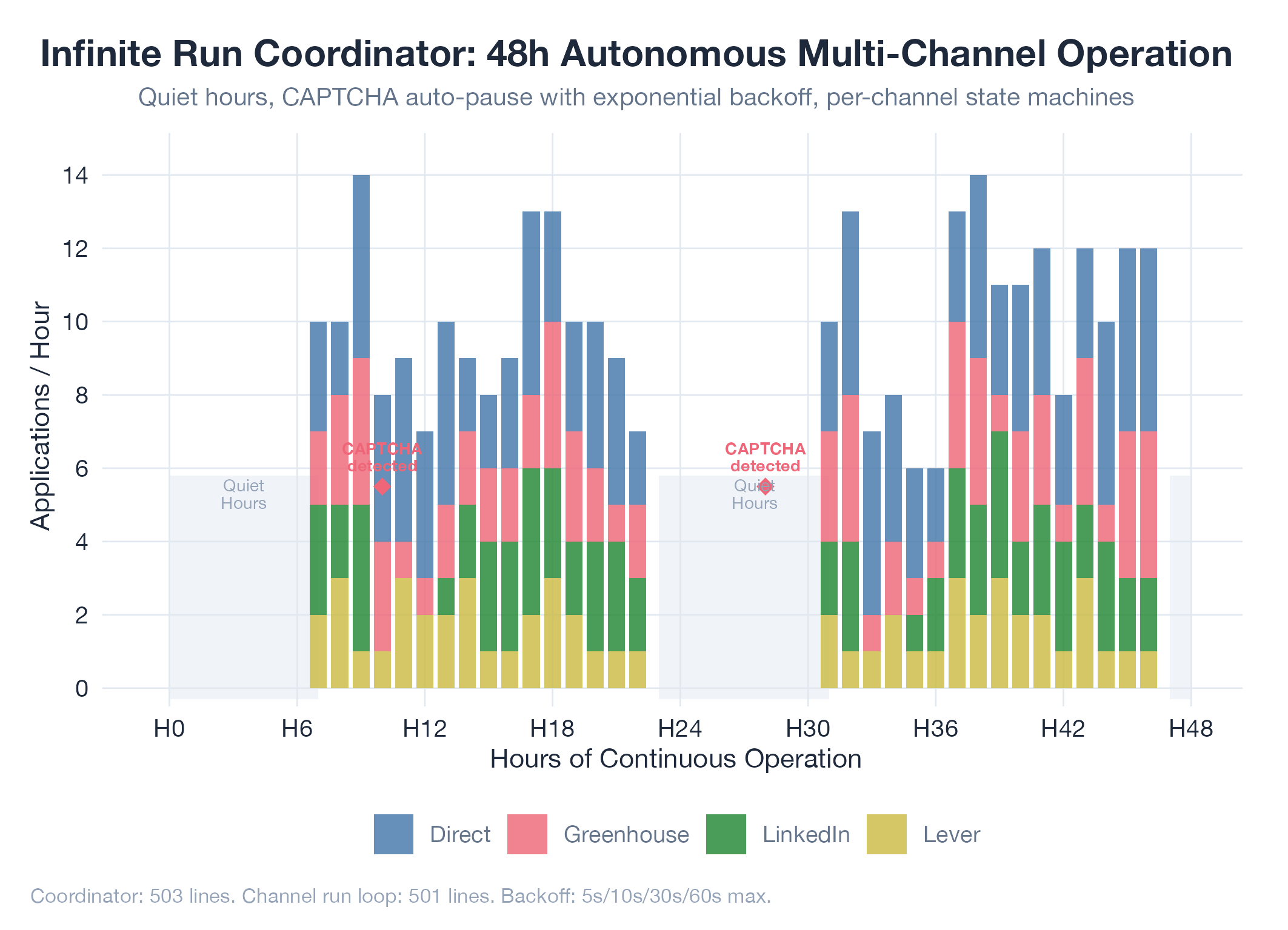
I built a full infinite run coordinator (503 lines) paired with a channel run loop (501 lines) that enables continuous multi-channel parallel job application. The coordinator maintains a state machine per channel (LinkedIn, Greenhouse, Lever, Direct) so one platform’s hiccup never stalls the others. Quiet hours stop work during the overnight window that looks suspicious to bot-detection. Stagger delay spaces channel launches so they do not light up the same Chrome profile at the same second. Daily application limits cap noise-to-signal. CAPTCHA detection auto-pauses the affected channel and surfaces a notification rather than burning attempts. Exponential backoff (capped at 60 minutes) handles transient errors gracefully. Checkpoint tracking records stage durations so I can see where time is going. Abort handling flushes in-flight state cleanly on SIGTERM.
Impact
This turned jobs-apply from a single-run tool into a persistent autonomous engine. The coordinator now runs 24/7, respecting quiet hours and rate limits, automatically recovering from errors, and pausing only on true CAPTCHA walls. The architecture still powers the production system more than a month later. Every later feature (multi-process isolation, tenant scoping, the SaaS deployment, the desktop app) plugged into this coordinator rather than replacing it. The state-machine-per-channel pattern became the shape every later adapter assumed by default.
The meta-observation: a coordinator is an investment in time, not in features. The first version of an automation tool wants to be a script. The second version wants to be a service. Crossing that gap requires treating failure modes as first-class citizens rather than as edge cases. Quiet hours, stagger delay, and exponential backoff are not features the user sees. They are the reason the user never has to see the tool at all. That inversion (from foreground tool to background infrastructure) is the phase change that makes a job-application engine useful rather than a curiosity.
Source
experiments/jobs-apply/2026-03-09-four-opus-sub-agent-orchestration